기초 데이터
새해를 맞이하여 운수대통의 기운을 점검할 겸 로또 6/45 분석을 하고자 한다.
분석 도구로는 R을 사용하고자 한다.
로또 회차별 당첨번호는 아래 공식사이트에서 제공 중이다.
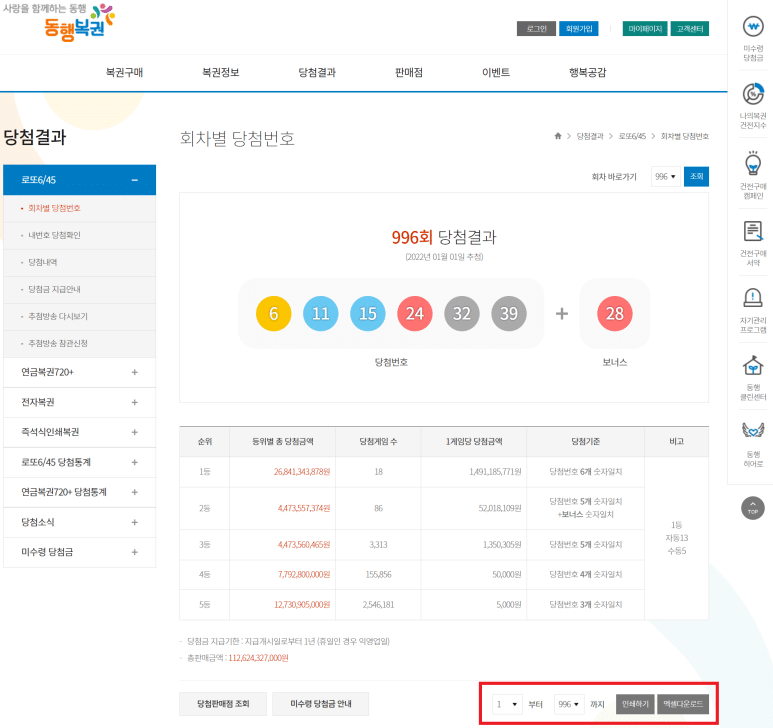
회차를 1회차부터로 설정하고 엑셀다운로드를 하면, excel.xls 라는 파일이 생성된다.
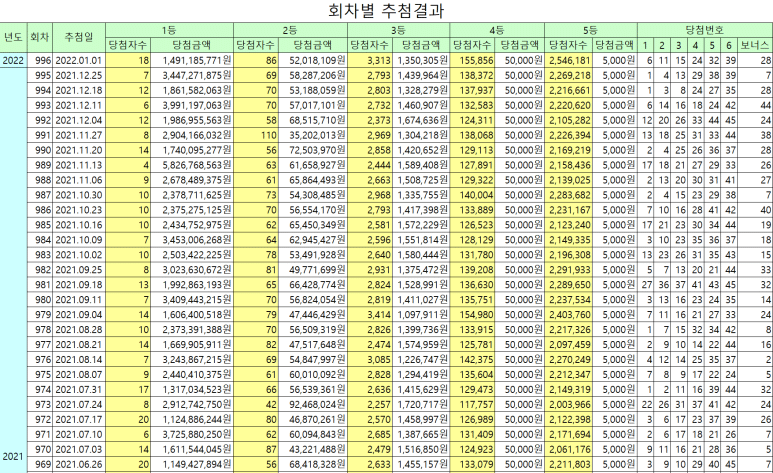
R을 통하여 분석할 대상은 바로 이 엑셀 파일인 것이다.
유의할 사항은, 번호별 단순 통계는 공식사이트에서 이미 제공하고 있다는 것이다.
하지만 이런 분석에 만족할 수는 없기에 R을 통하여 추가분석하는 것이라 하겠다.
먼저 분석할 것은, 공식사이트 통계에서 따로 제공하지 않는 연도별 평균 1등 당첨금액과 해당 연도별 이월횟수 동시 분석이다.
데이터셋 불러오기
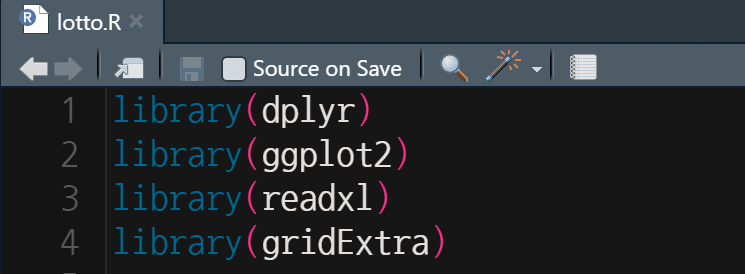
먼저 분석에 필요한 라이브러리를 불러온다 (순서 무관, 대문자는 꼭 대문자로 입력)
dplyr 라이브러리는 데이터 편집/가공에 필요하고,
ggplot2 라이브러리는 그래프 표시,
readxl 라이브러리는 엑셀 불러오기,
gridExtra 라이브러리는 ggplot2 그래프를 하나의 화면으로 합칠 때 각각 필요하다.
이제 상기 excel.xls 파일을 R로 불러온다.
사실 excel.xls 원본 파일은 엑셀로 로딩하면 알겠지만, 불완전한 상태로 공식사이트에 업로드되어 있다.
이를 바로 R로 읽으면 에러가 발생하는데, R에서의 문제가 아니고 엑셀 파일 자체의 문제이다.
따라서, 이를 고치고자 excel.xls를 엑셀로 먼저 읽으면 나타나는 다음 메시지를 일단 ‘예’를 선택해 연다.

그리고 다시 [저장하기]를 누르거나, 원하는 파일명으로 [다른 이름으로 저장하기]를 한다.
여기서는 lotto.xlsx로 [다른 이름으로 저장하기]를 하고 진행하였다.

파일명 앞에 있는 폴더명은, 각자의 파일 위치에 맞게 수정하면 된다.
(ex. 바탕화면에 저장한 경우, (“C:/desktop/lotto.xlsx”, skip =2)로 사용)
여기서 skip =2 옵션을 왜 주었는지 의아해 할 수가 있는데, 이는 필요없는 상단 행을 처음부터 제거하고 불러올 때 유용하기 때문이다.
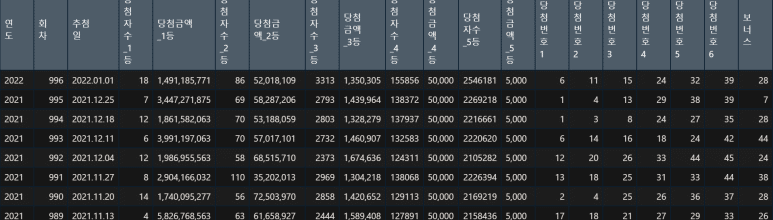
엑셀 화면을 보면 알겠지만, 최상단 ‘회차별 추첨결과’는 필요없는 행이고, 그 아래 2행은 꼭 불필요하다 할 수는 없지만, 3행이 가장 열 특성을 잘 나타내고 있어 1~2행을 제거하였다.
여기서 의문이 들 수 있다.
처음부터 전체를 불러오기한 다음 R에서 따로 제거해도 되지 않냐고 할 수 있는데, 그래도 되기는 하지만, 기본적으로 최상단 행을 R에서 열(속성) 명으로 간주하기 때문에 데이터 구조가 훨씬 더 복잡해질 수 있다. 따라서 시간 절약도 할 겸 처음부터 필요없는 최상단 행을 skip 옵션을 통해 제거해주는 것이다.
skip=2 옵션을 통해 3행부터 원본 데이터를 불러올 경우, 다음과 같은 lotto 데이터셋이 생성된다.
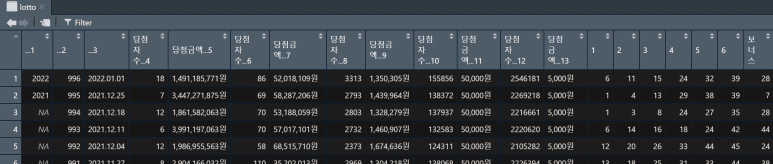
데이터 전처리
3행이 기본적으로 열(column) 이름으로 나타나나, 그래도 언뜻 이해하기 어려운 상황이다.
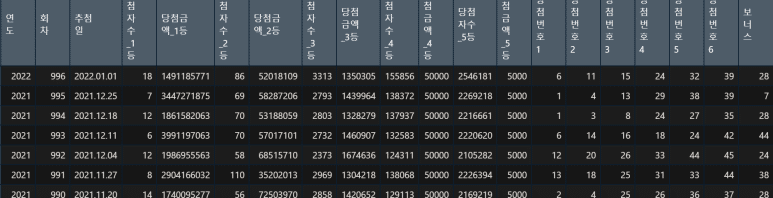
따라서 각 열 이름을 다음의 dplyr 라이브러리 명령어인 rename 함수를 써서 이해하기 쉽게 일괄 바꿔준다.

그러면 아래와 같이 lotto 데이터셋이 바뀐다.
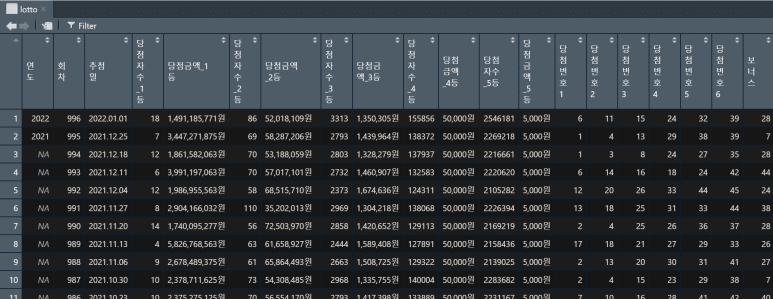
그런데 1열인 연도 속성에 문제가 있어 보인다.
원본 엑셀에서는 2021년 셀이 병합되어 있었는데, R에서는 이를 다 분리해서 읽다보니 연도 열 3행부터는 모두 자료가 없음(null)을 의미하는 NA 상태다.
따라서 연도별 통계를 할 때 NA 상태로 있으면 제대로 분석이 될리 없으므로 이를 채워야 한다.
다양한 방법이 있을 수 있겠지만, 다행스럽게도 추첨일(3열)이 따로 있어서 이를 활용하는 것이 쉬워보인다.
즉, 추첨일(3열) 앞 4자리(연도) 부분만 추출해 연도(1열)에 입력하는 식이 제일 무난해보인다.

mutate 활용법은 본 블로그의 dplyr 글을 참조하길 바라고, substr 함수는 R의 자체 내장 함수로서 특정 데이터를 추출하는 기능은 한다.
즉, 상기 스크린샷에서의 의미는, lotto$추첨일 열에서 1(첫째자리)에서 4(4자리)를 추출하여 연도 열에 입력하라는 뜻이다.
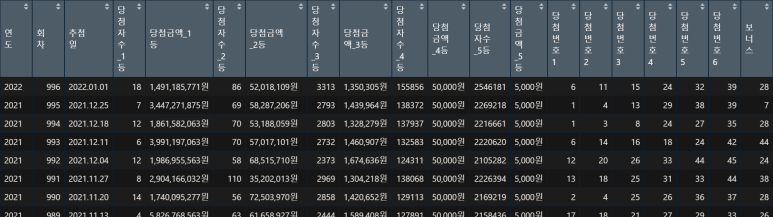
그러나 로우데이터를 전처리(분석하기 전에 데이터를 다듬는 일)하는 것은 여간 번거로운 일이 아니다.
str 명령어를 통해 각 열의 형태를 보면, 당첨금액_1등, 당첨금액_2등… 이 숫자였으면 좋겠지만 사실은 “xxx,xxx원” 식의 문자열이다. 따라서 이를 숫자로 바꿔줄 필요가 있다.
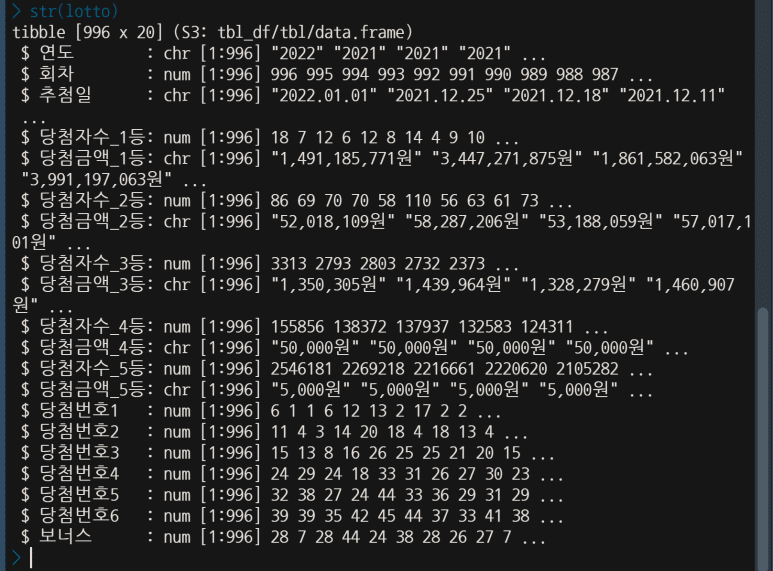
상기 화면에서, 각 당첨금액 열은 num(숫자형)이 아니고 chr(문자형)으로 되어있는 것을 알 수 있다.
숫자로 변환하기에 앞서, 당첨금액에서 ,(콤마), 원(문자)를 제거하여 숫자만 남겨놓아야 한다.
따라서 이 문자들만 찾아서 제거하기로 한다.
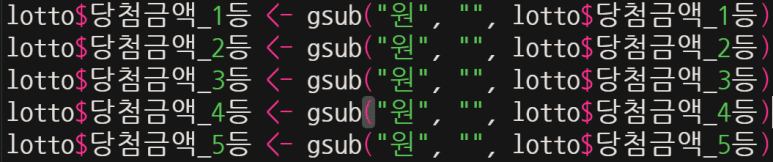
위의 gsub는 substr 함수와 마찬가지로 내장 함수로서, “원”이라는 문자를 “”(제거)로 바꾸라는 의미다.
“원”이라는 문자는 일단 제거하였고, 이번에는 ,(콤마)도 제거해보자.
또, 숫자만을 남겨놓는다고 해서 자동으로 숫자형(num)으로 속성이 바뀌는 것은 아니므로 as.numeric 함수를 통해 숫자형 변환도 동시에 진행한다 (참고로 1열 연도 속성도 문자형이므로 같이 변환).

이제 기본적인 전처리는 끝났다.
분석
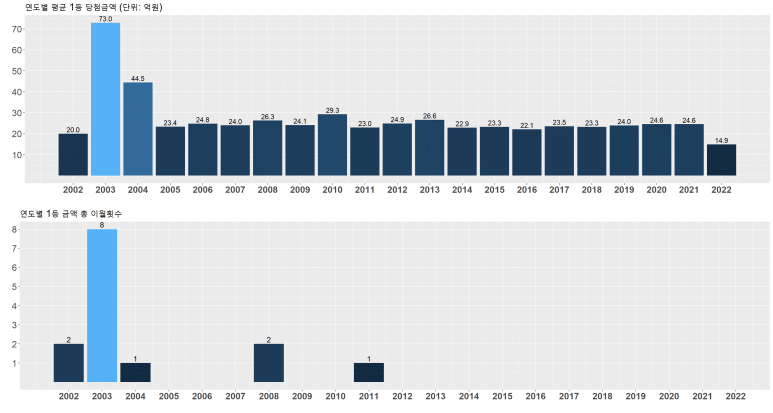
연도별 평균 1등 당첨금액
본격적으로 데이터 분석을 시작하자.
연도별 평균 1등 당첨금액을 분석하려는데, 1등이 없어 이월된 회차의 경우 1등 당첨금액이 0원으로 입력되어 있어 평균을 구할 때 왜곡될 수 있다. 따라서, 1등 없는 회차(이월된 회차)는 제외하고 평균을 구하고, 이 때 금액 단위가 크므로 억원 단위로 표시하자.
그리고 이를 lotto1 이라는 별도 데이터셋으로 저장한다.
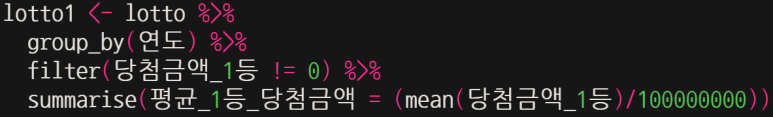
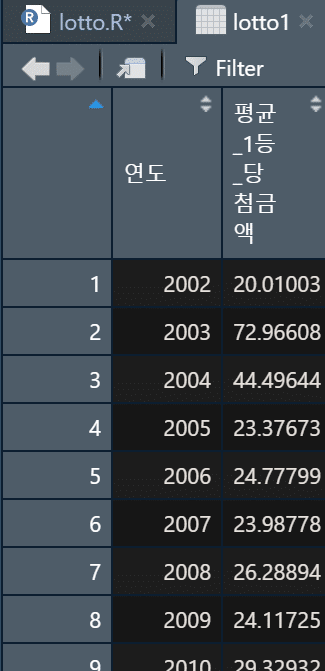
그리고 이를 바로 ggplot을 통해 그래프로 표시하면 아래와 같이 나타날 것이다.
(자세한 ggplot 함수 활용법은, 본 블로그 별도 게시물 참조)
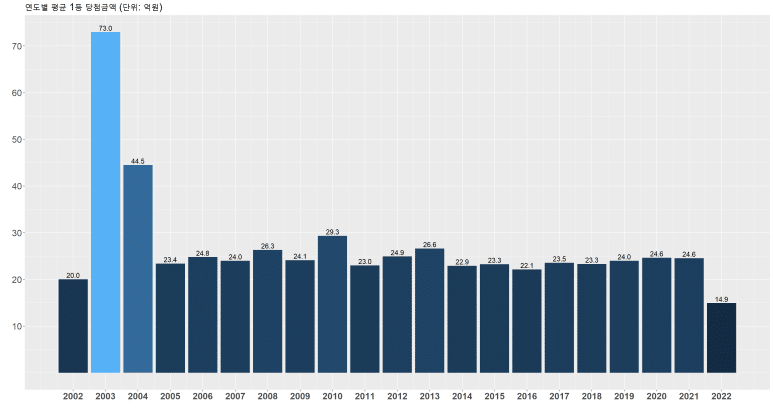
하지만 이것만을 제시하게 되면, 앞서 평균을 구할 때 당첨금액이 0인 회차(이월 회차)를 임의로 제거하고 산출했으므로 왜곡된 메시지를 전달할 수 있다. 따라서 연도별 이월횟수를 동시에 제공하는 것이 보다 더 정확한 전달일 것이다.
연도별 이월횟수
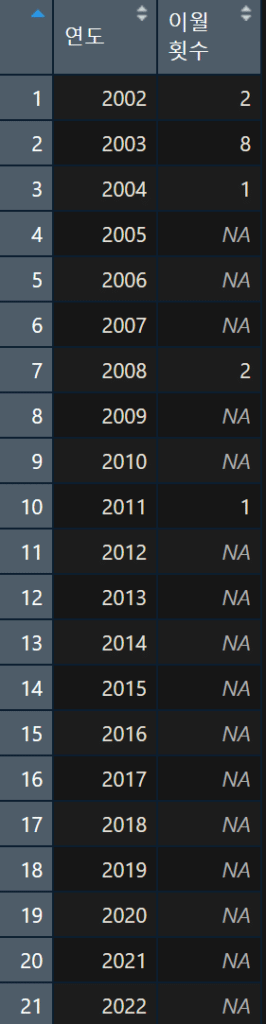
따라서 이번에는 연도별 이월횟수를 구해보자.

하지만 이렇게만 하면, 연도별 이월횟수가 0인 연도가 누락돼서 산출된다.
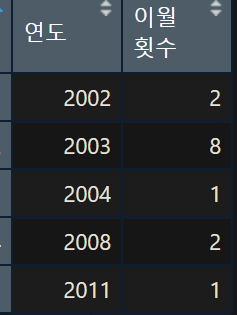
이를 그대로 활용할 경우, x축이 2002년, 2003년, 2004년, 2008년, 2011년만 표시되어 앞서의 그래프와 x축 단위가 맞지 않아 비교하기 힘들다. 또, 이외 연도가 이월횟수가 0이라는 표시도 해 줄 필요가 있다.
따라서 별도 연도 데이터를 생성해서 합친다.

여기서 left_join 함수는 데이터끼리 병합할 때 쓰는 것으로, 엑셀로 치면 vlookup 기능을 한다 보면 된다.
즉, lotto1c를 기준으로 이에 일치하는 값을 lotto1b로부터 붙인다는 뜻이다.
이제 lotto1d를 기준으로 ggplot을 통해 그래프 표시하면 아래와 같이 된다.
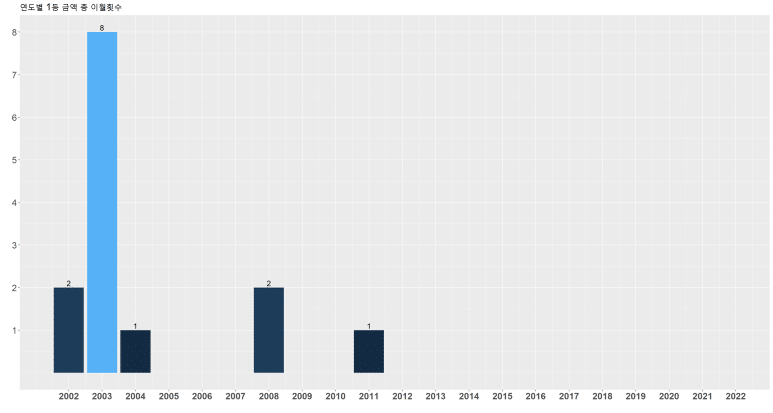
그리고 이를 하나의 화면으로 합치고자 할 경우, 앞서 로딩한 라이브러리 gridExtra에서 제공하는 grid.arrange 명령어를 통해 함께 표시할 수 있어 가독성을 높일 수 있다.
사용방법은 앞서 각각의 ggplot 함수 앞에서 별도의 데이터셋 지정(ex. gg1 <- , gg2 <-)을 한 다음, grid.arrange(gg1, gg2)와 같이 해 주면 된다.

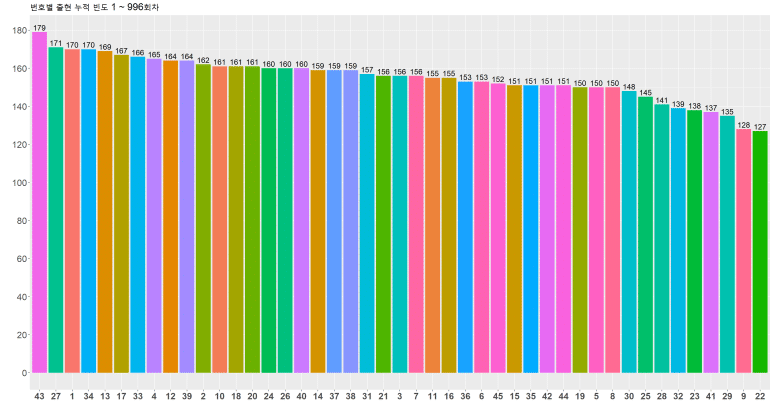
번호별 출현 누적 빈도 수
이번에는 번호별 출현 누적 빈도 수를 구해보고자 한다.
아래와 같이 각 당첨번호에 해당하는 열을 따로 추출하여 별도 데이터셋을 생성한다.
(데이터셋[ , ] 용법은 본 블로그 R 기초 편 참조)
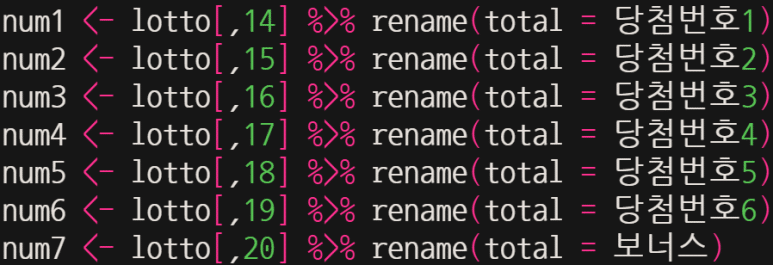
여기서 별도로 rename을 통해 total 이라는 열 이름으로 통일시키는 이유는, 하나로 병합하기 위함이다. 병합하고자 할 때는 기준 열 이름이 같아야 하는데, 같지 않으면 에러가 발생하기 때문이다.

이제 num 이라는 데이터셋에 당첨번호1~6에 해당하는 숫자들이 구분없이 하나의 열로 병합되었다.
이를 빈도수 별로 카운트해 보자.
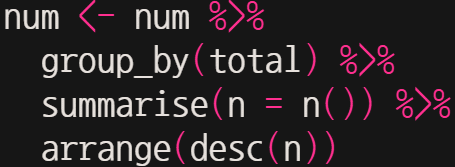
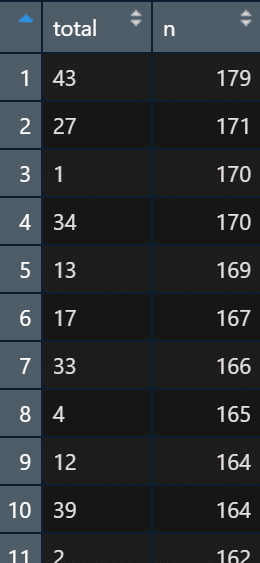
이를 그대로 ggplot을 통해 표시할 경우, 아래와 같이 나타난다.
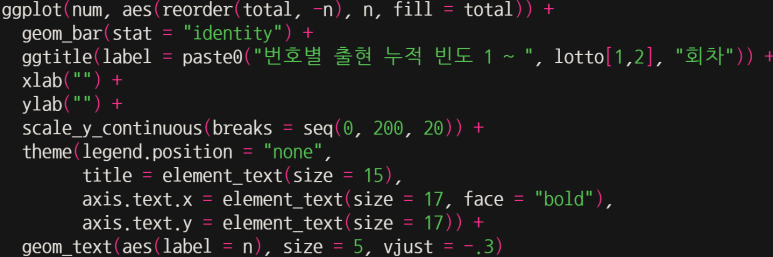
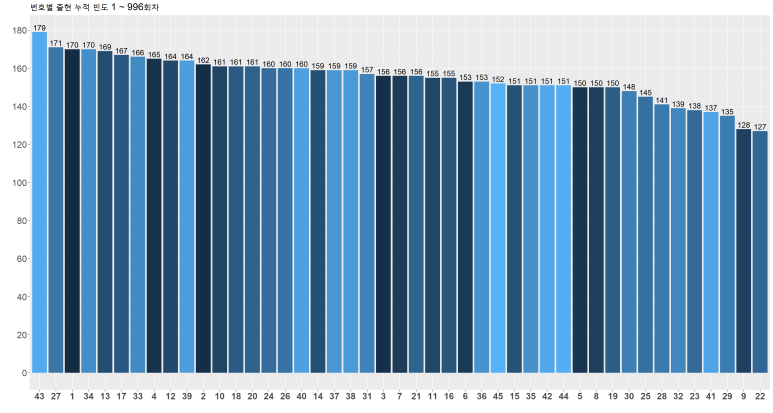
색상들이 별로 다채롭지 않게 나타나는 이유는, x좌표에 해당하는 total 값들이 숫자형으로 인식되어 있기 때문이다. 따라서 심미성을 높이려면, total 값들을 문자형으로 바꾸어주면 보다 화려하게 나타낼 수 있다.