
R – ggplot 설치
R의 대표적인 그래프 시각화 관련 라이브러리인 ggplot2를 중심으로 이야기하고자 한다.
library(ggplot2)를 먼저 실행해야 하고,
만약 라이브러리가 없어 에러가 발생한다면 install.packages(“ggplot2”)를 통해 설치한다.
(여기서 “ggplot2″로 따옴표를 양쪽에 붙여야 에러가 발생하지 않는다,
비슷한 용법으로 library(“ggplot2”)를 해도 인식이 되나, library 명령어는 따옴표를 생략해도 무방하다)
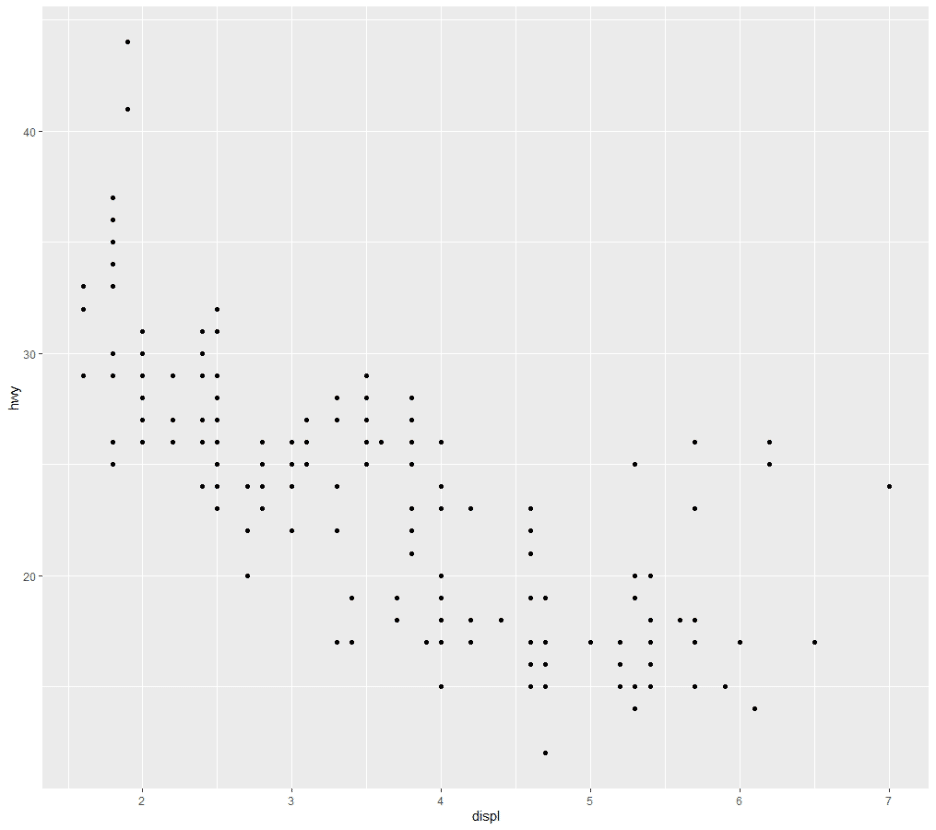
다음과 같이 구문을 실행하면, 아래와 같은 그래프가 표시된다.
(참고로, mpg 데이터는 ggplot2 라이브러리에 포함된 것으로, R 기본 내장 데이터가 아니다. 데이터의 의미는 미국 환경보호당국이 수집한 38개 차량에 대한 관측값으로서, displ은 배기량, hwy는 고속도로 연비를 뜻한다)

지옴함수의 구조
즉, ggplot(data = 데이터명, mapping = aes(축)) + geom_지옴함수() 의 구조다.
사실, 여기서 ‘data =’ / ‘mapping =’ 텍스트는 생략해도 인식한다. 따라서 이후부터는 생략하겠다.
다음 두 가지의 형태는 결과적으로 차이가 없다.
(‘mapping =’ 에 해당하는 구문을 지옴함수에 써도 된다는 얘기다)

하지만 겉보기와 달리, 도출되는 그래프가 같다 해서 과정까지 같은 것은 아니다.
즉, ggplot에 매핑함수(aes 등)를 바로 입력할 경우, 다음 나오는 지옴함수들이 이를 공유하게 된다.
하지만, 두 번째와 같이 매핑함수를 지옴함수에 입력할 경우, 해당 지옴함수만 이를 반영한다.
즉, 지옴함수는 포토샵의 레이어처럼 중첩 표시되기 때문에, 지옴함수를 여러 개 연이어 쓸 수 있고, 이 경우 그래프 역시 중첩 표시된다.
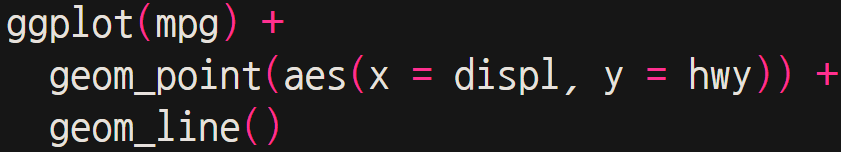
상기와 같이 구문을 작성할 경우, 아래와 같이 에러가 발생한다.

이는 geom_line()의 경우, 공유되는 x, y축이 없기 때문이다.
여기서 해결책은, ggplot(mpg, aes(x = displ, y = hwy)) 로 고쳐주거나
아니면 geom_line(mpg, aes(x = displ, y = hwy)) 처럼 해당 지옴함수에도 똑같이 입력해주는 것이다.
물론 좌표를 각각 다르게 하여 중첩하고 싶다면 지옴함수마다 별도의 축을 매핑해주어야겠지만,
이 경우처럼 동일한 축을 사용하고자 할 경우는 효율성 측면에서,
ggplot 함수에 모두 매핑하고, 나머지 지옴함수는 ()로 빈 칸으로 두는 것이 간결할 것이다.
레이어처럼 중첩되는 효과란, 어떤 형태를 말하는 것인지는 아래 그래프로 설명한다.

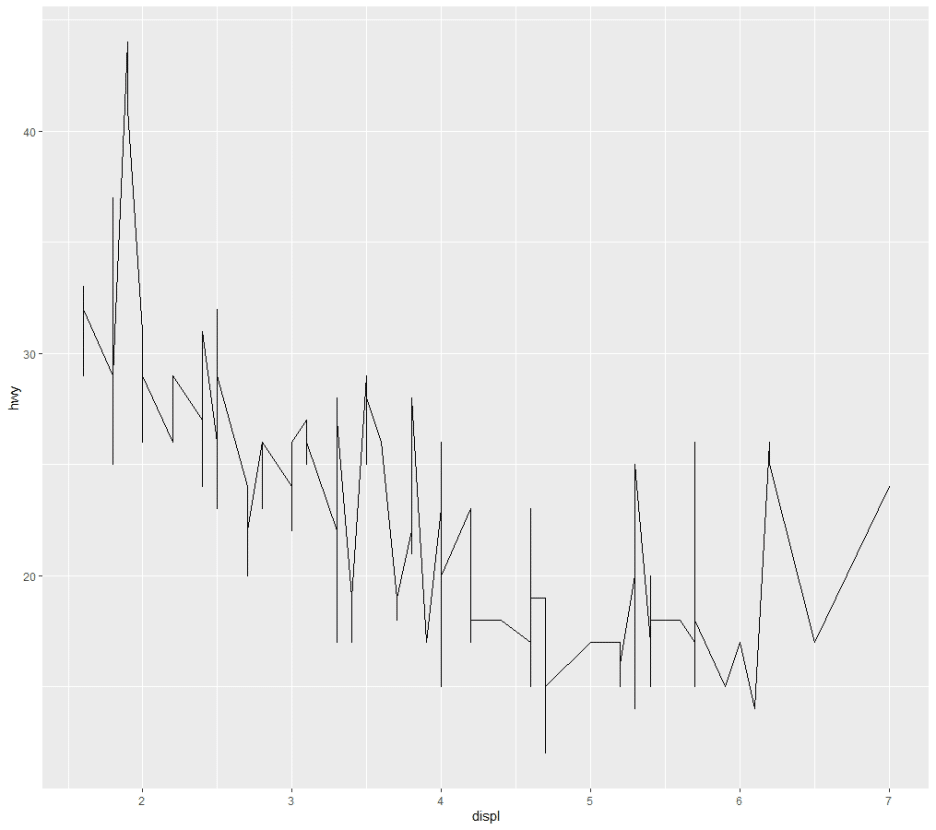
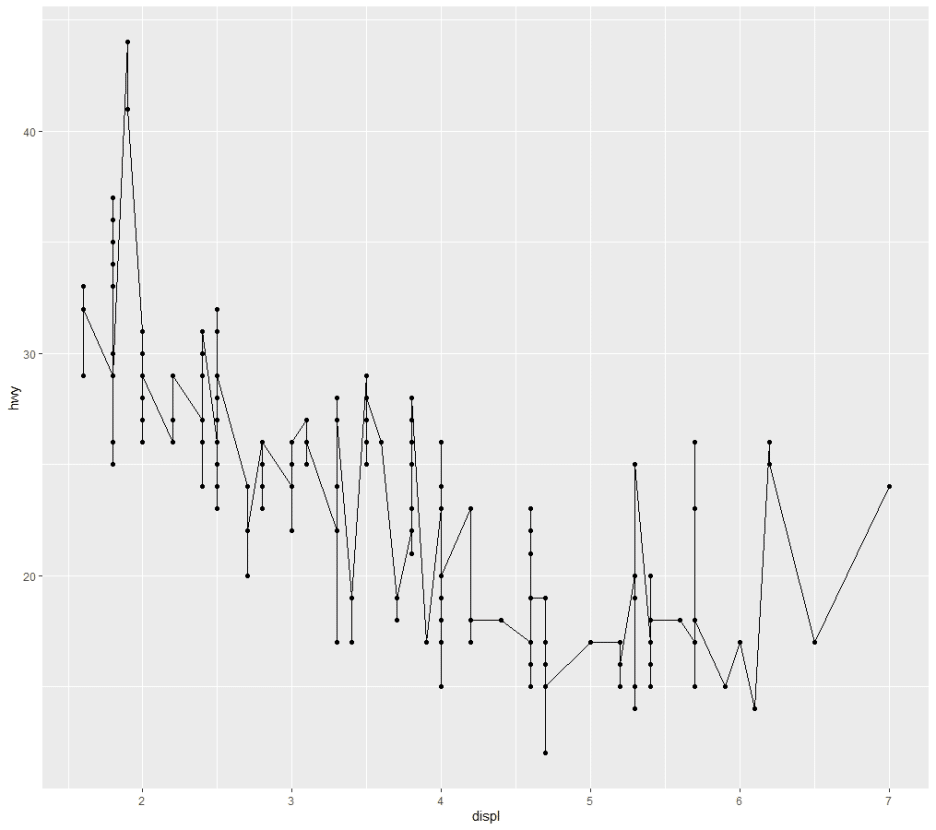
산점도
즉, geom_line() 단일 지옴함수로만 실행하면 해당 선 그래프만 표시되는 반면,
geom_point()를 동시에 입력할 경우, 산점도(점)까지 선 그래프 위에 중첩해 표시되는 것을 확인할 수 있다.
다시 말해서, ggplot 함수는 용법에 따라 매핑을 ggplot()에 공통적으로, 또는 이를 비우고 각각의 지옴 함수에 개별 적용할 수 있고, 이 때 지옴 함수가 추가될 때마다 중첩 표시됨을 알 수 있다.
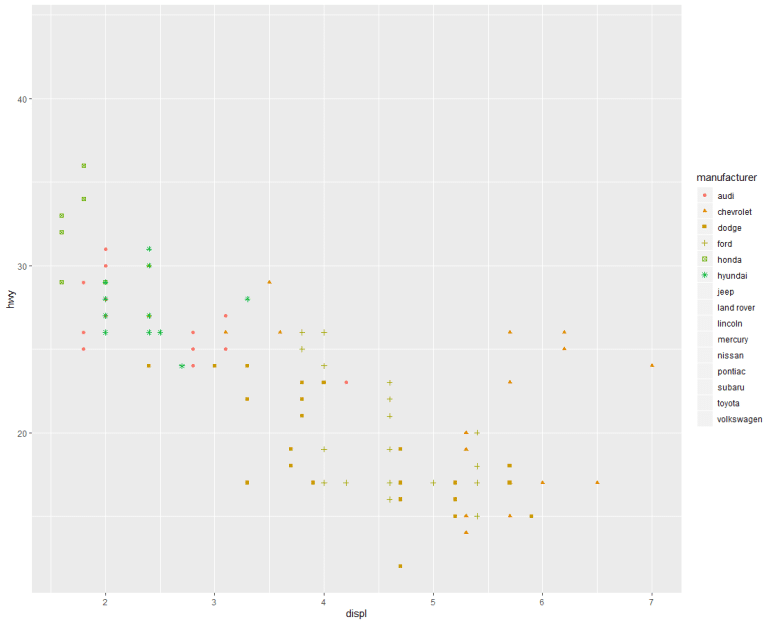
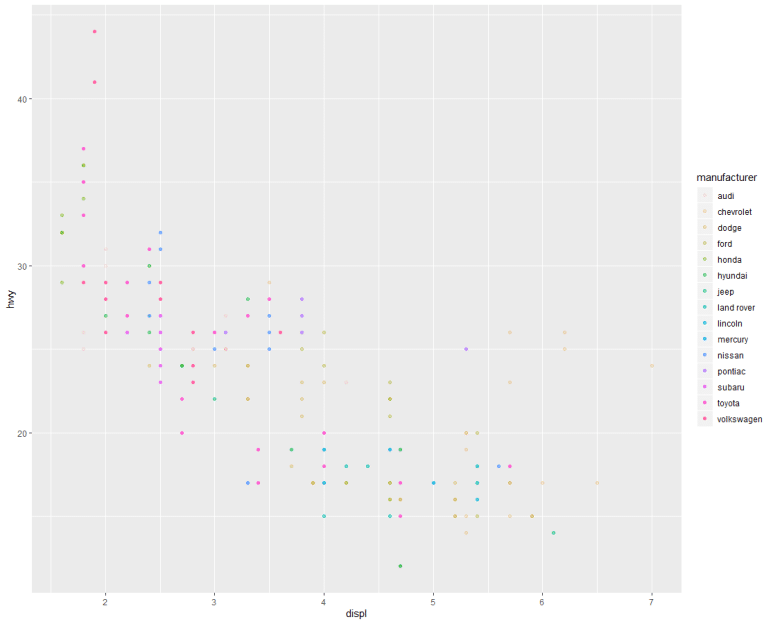
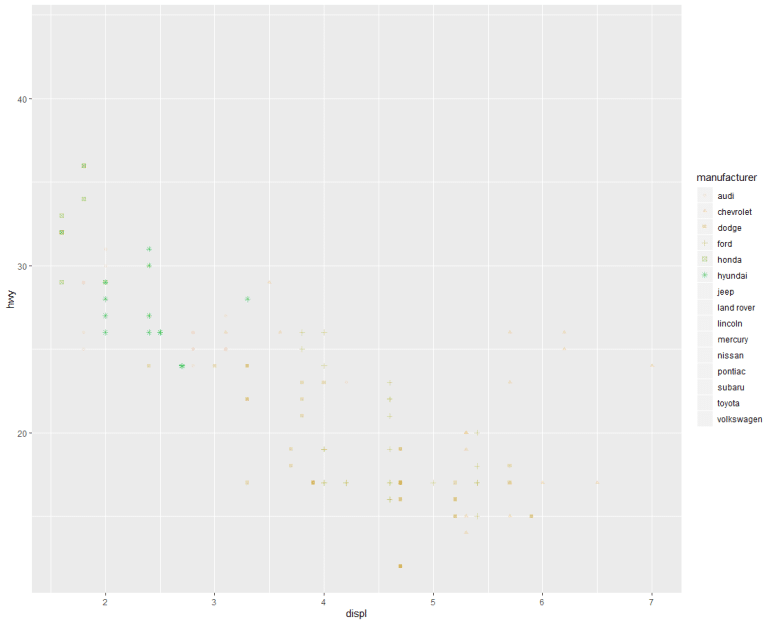
한편, aes()의 본래 풀 네임은, aesthetics로서 ‘심미성(미학)’을 뜻한다. 즉, ggplot 함수가 어떤 방식으로 아름답게(?) 그래프를 표현할지 알려주는 구문이라 할 수 있다. 조금 전에 aes()에 x, y 좌표만을 표시했다면, 이번엔 좀 더 문구를 추가해보자.
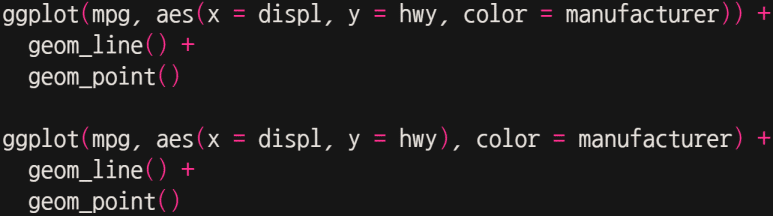
결과는 순서대로 다음과 같이 나온다.
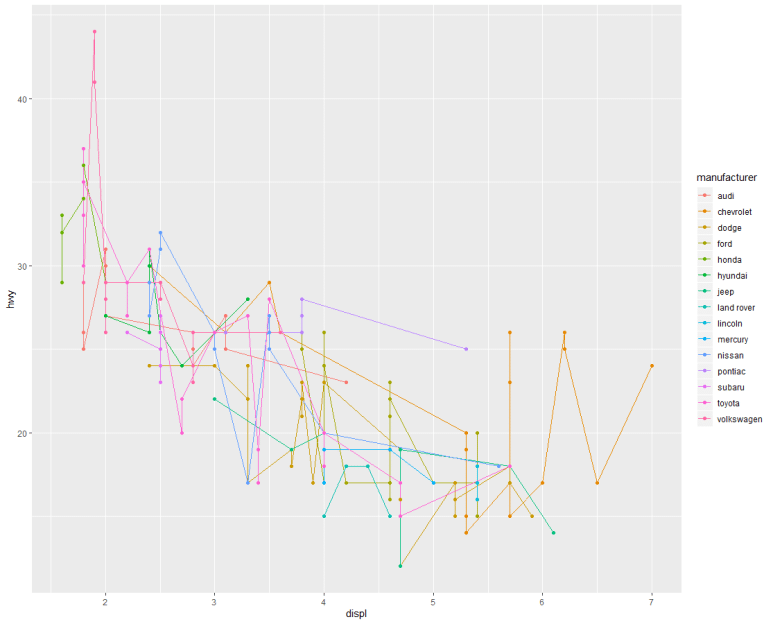
같은 데이터지만, 전자는 그래프가 제조사별 색깔 구분되었고, 후자는 단색으로 색깔 구분없이 하나로 그려졌다. 왜일까?
그렇다. color = 구문을 aes() 안에 썼느냐, 아니면 바깥에 썼느냐의 차이다.
즉, aes() 안에 구분적인 요소를 써 줘야 color 속성 역시 구분되어져 표시된다.
하지만, aes() 바깥에 쓴 color = 구문은 구분 표시되지 않는다.
비슷한 구문으로서, shape =, alhpa = 구문이 있고 각각 점 모양, 투명도(1에 가까울수록 불투명)를 의미한다. 이 구문들은 동시 적용도 가능하다.

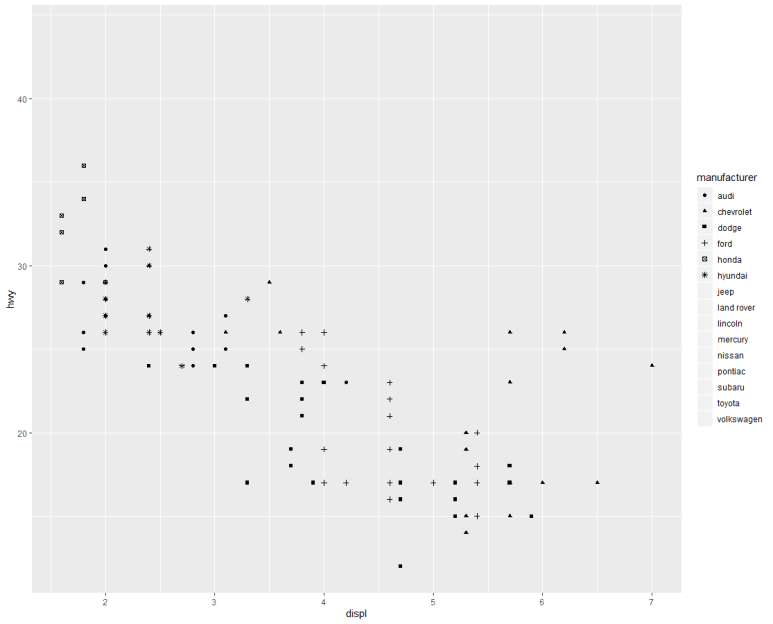

선 그래프
이번엔 geom_point를 이용한 산점도가 아닌, geom_line을 활용한 선 그래프로, 여러 레이어를 선 종류로 구분해 나타내는 법을 알아본다.
(참고로, 아래 두 구문은 결과가 같다 / drv 속성은 차량 구동방식 종류를 의미한다 -4륜구동 / 전륜구동 / 후륜구동)
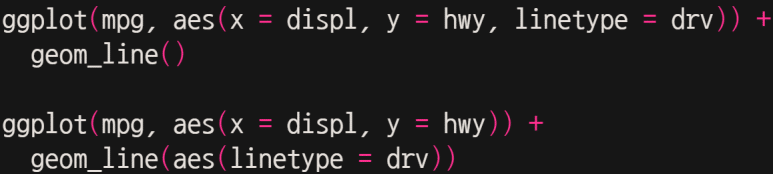
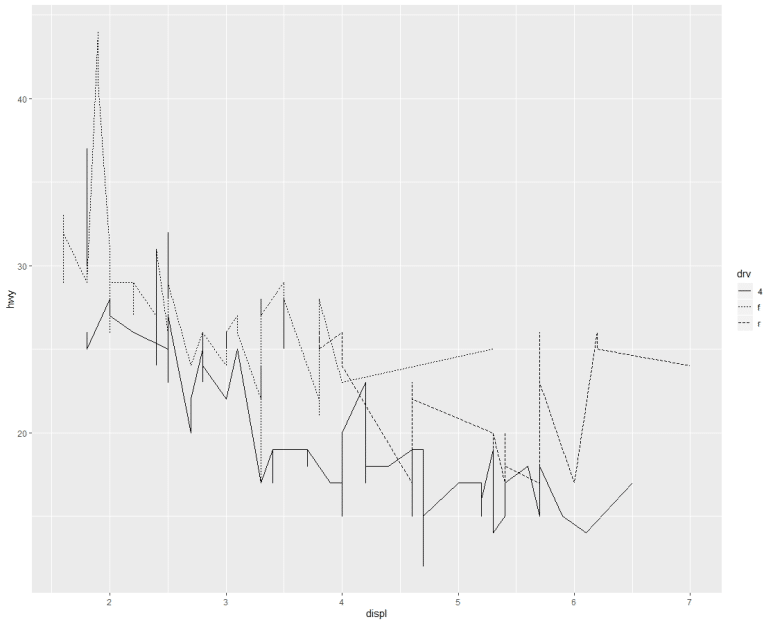
선의 종류가 자동으로 선택되어 구분되었다. 그러나 특별히 원하는 선의 종류가 있다면, 어떻게 따로 적용할 수가 있을까?
선(line)의 종류
선의 종류는 다음과 같다 (아래 그래프는 자체 제작함).

이 중 세 가지를 선택하여, drv = 4 , f, r 에 대해 순차적으로 적용시켜보자.

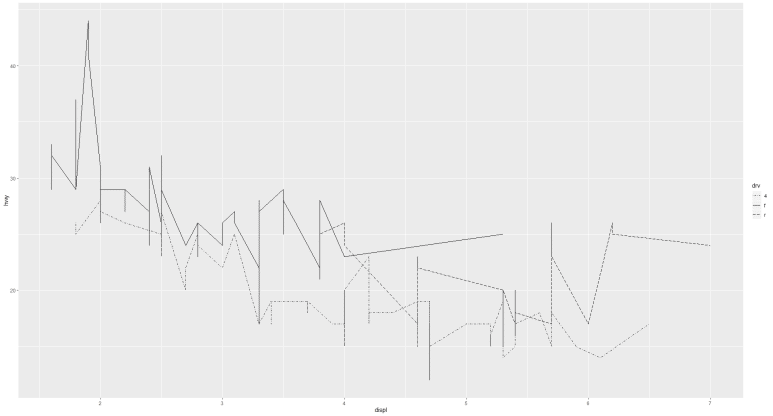
먼저 도출한 그래프와 비교하여, 선의 그래프 종류가 바뀐 것을 알 수 있다.
그래프 두께가 가늘어서 큰 차이가 눈에 띄지 않는다면, 다음과 같이 두께를 변화시켜보자 (lwd = 숫자).

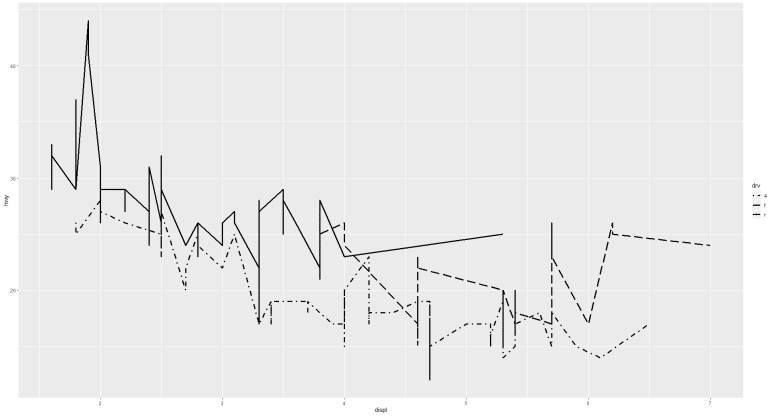
복수의 그래프
지금껏 여러 그래프를 하나의 중첩된 레이어로 그렸다면,
이번엔 한 좌표당 하나의 레이어만 표시하여 다수의 그래프가 한꺼번에 생성되도록 하는 법을 알아보자.

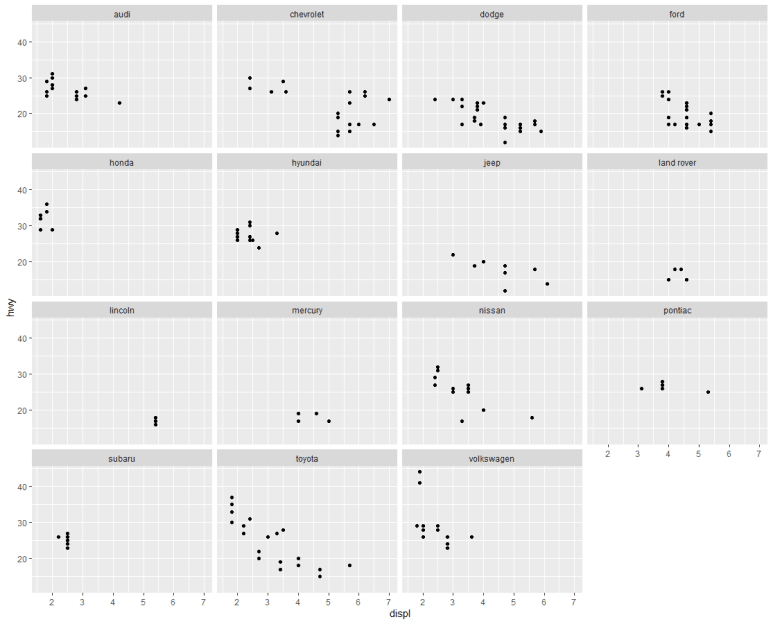
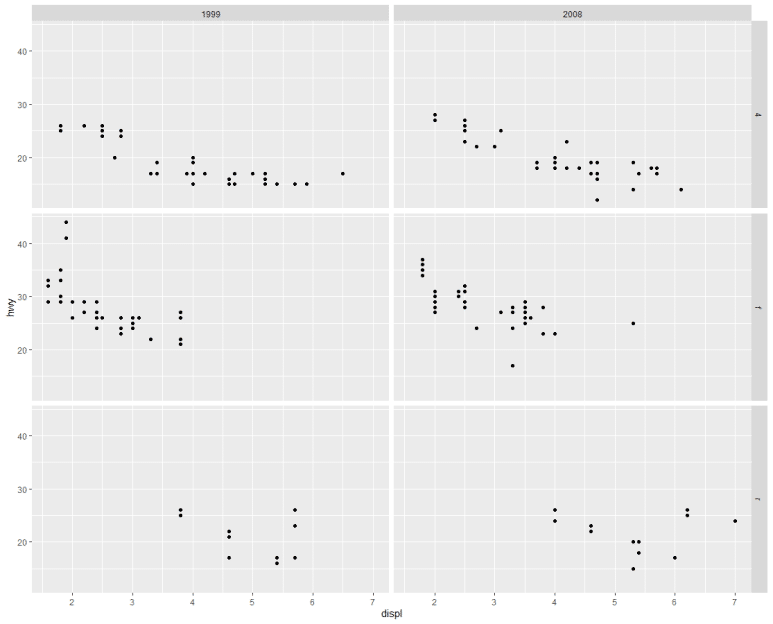
즉, 기존 ggplot 구문에 facet_wrap(~ 구분할 변수, nrow = 행 수)만 덧붙이면 각각의 개별 그래프들을 손쉽게 얻을 수 있다. 기준값을 변수 하나로 했다면, 이번에 두 개 변수를 기준으로 나타내보자. 이 때는, 다음 같이 facet_wrap 대신 facet_grid(변수1 ~ 변수2) 로 바꿔주면 된다.

막대그래프
기초
이번에는 좀 더 멋있는(?) 막대그래프를 그려보고자 한다. 바로 geom_bar() 함수이다.
(여기서 주의할 점은, geom_bar()는 정확하게 말하면 ‘누적’ 막대그래프이다)
먼저 기본 용법을 알아보자. 다음 같이 간결하게 코딩한 후 실행시켜보자.
(사실, 3개의 구문은 같은 그래프를 도출한다)
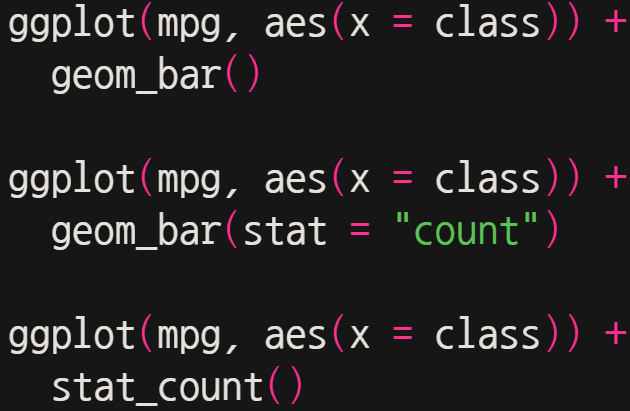
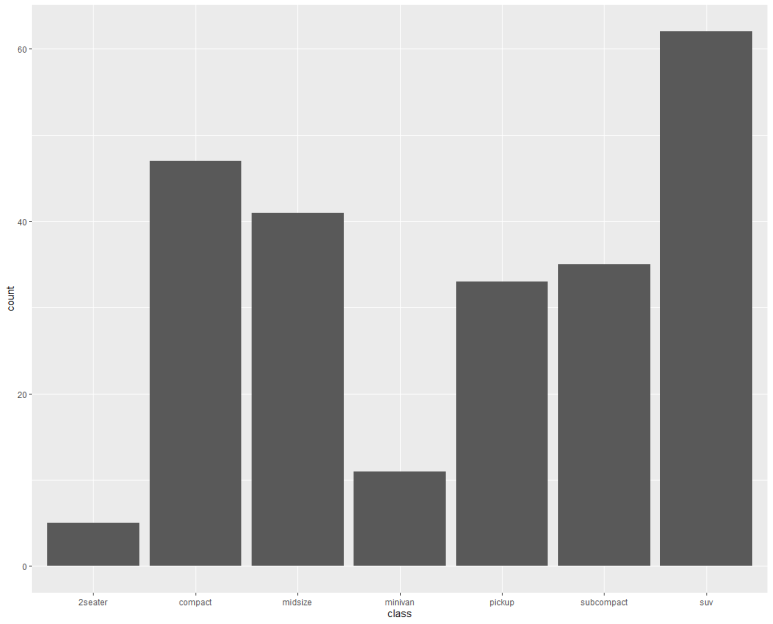
왜 세 개의 다른 구문이 같은 그래프를 만드는 것일까?
그것은 기본적으로 geom_bar()로 간결히 작성할 경우, 기본값이 적용되기 때문이고 그 생략된 기본값이 바로 (stat = “count”)이기 때문이다. 즉, x값에 해당하는 것을 (누적으로) 세는 것이 geom_bar의 기본 세팅이고, 이러한 동작은 stat_count() 함수와 같은 기능을 한다.
그렇다고, geom_bar()를 무조건 count 용도로서만 써야 하는 것은 아니고, 별도로 지정해줄 경우 count 기능이 아니라 별도 지정 값을 y축에 누적 표시하게 할 수 있다.
이 때 쓰는 옵션이 stat = “identity” 이다.
실습을 위해 임의로 3개의 열을 mpg 데이터에 추가해보자.
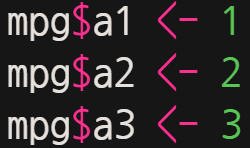
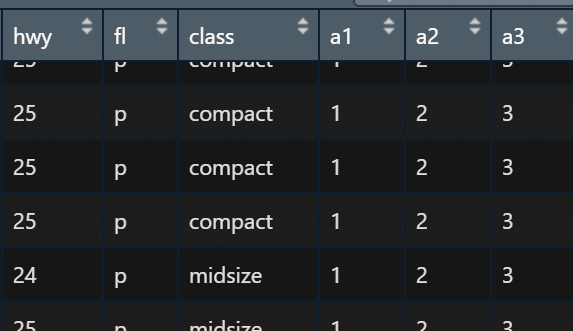
위와 같이, a1 열은 모두 1, a2열은 모두 2, a3열은 모두 3으로 하였다.
그리고 다음과 같이 입력해보자.
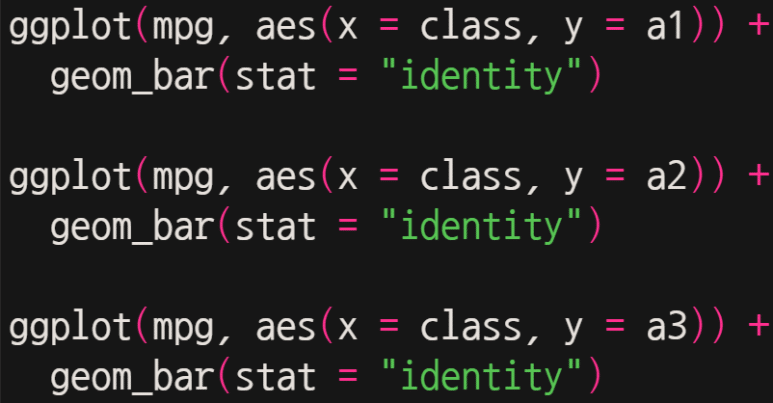
그러면 차례로 아래와 같이 각각 그래프가 산출된다.
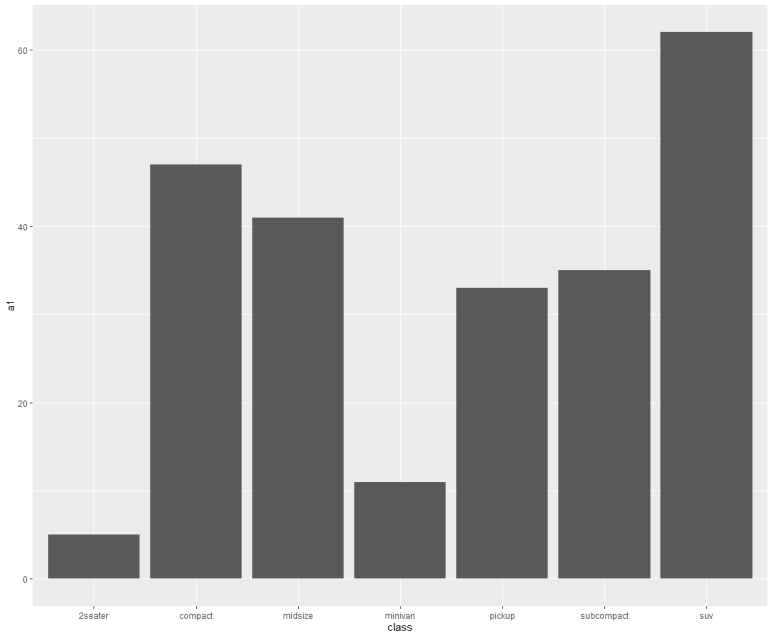
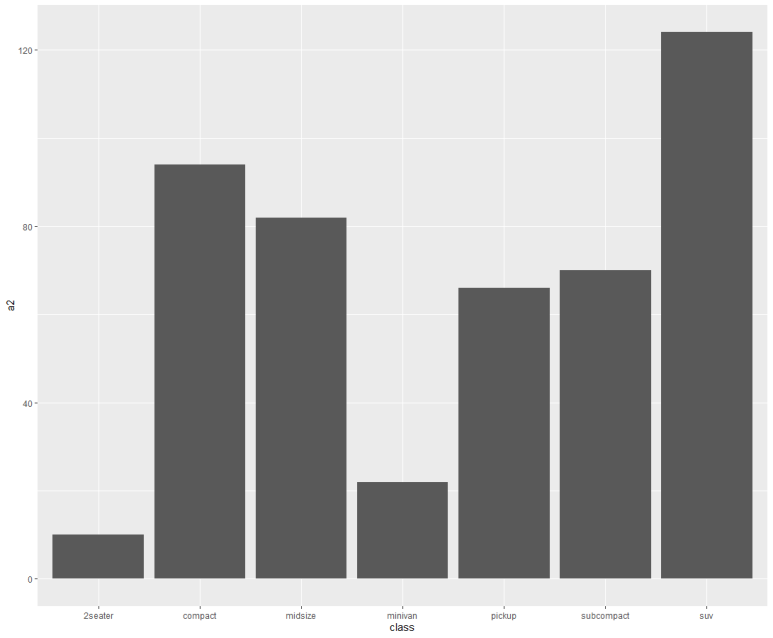
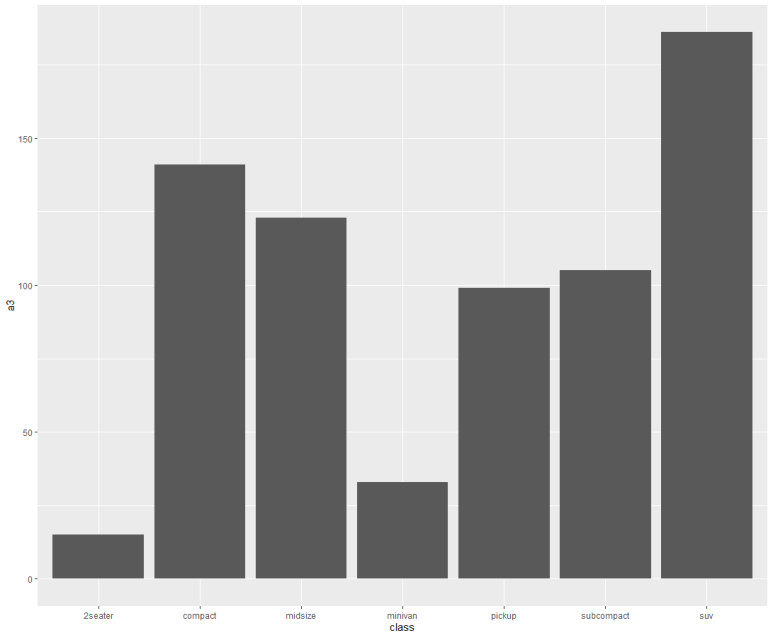
모양은 같지만, 자세히 보면 y축 단위가 다름을 알 수 있다.
즉, a1 기준 일때는 class별로 1씩 누적 카운트했다면, a2 기준일 때는 2씩, a3 기준일 때는 3씩 누적해서 합산한 것이다. 결국 그래프는 각각 1배, 2배, 3배로 카운팅된 값이다.
왜 이런 결과가 나오는 것일까? 이게 바로 count와 identity의 중요한 차이다.
즉, count는 직접 지옴함수가 세지만, identity는 직접 세지 않고 지정 y값을 단순 합산하기 때문이다. 따라서 a1에서 1로 카운트한 그래프는 count로 카운트한 그래프와 같을 수 밖에 없다.
그런데, 그래프의 크기별로 정렬이 되어 있지 않다보니 한 눈에 파악하기 어려운 것이 사실이다. 다시 말해, x좌표 순서를 바꿔볼 수는 없을까? 이 때 쓰는 옵션이 reorder = 이다. aes(x = reorder(x축, 정렬기준 변수))이다.
x좌표를 (평균) displ(배기량) 순으로 정렬해서 표시하려면 다음과 같이 하면 된다. 참고로, 기본값은 오름차순이고 내림차순을 원하면 -displ과 같이 정렬기준 변수 앞에 -(마이너스)를 붙인다.
여기서부터는 앞에서 data =, mapping = 을 생략했듯, x=, y= 도 생략하도록 하겠다. 즉, aes()는 첫번째, 두번째를 자동으로 x축 변수, y축 변수로 인식한다.

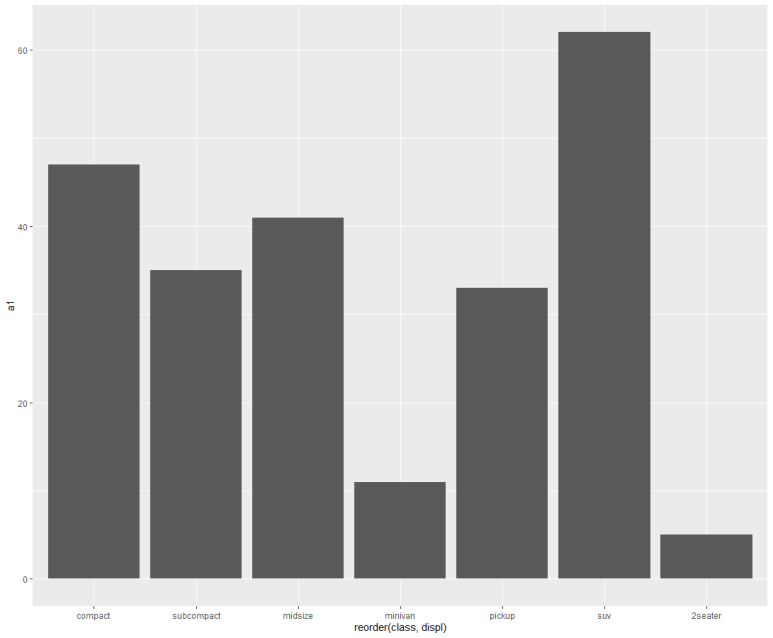
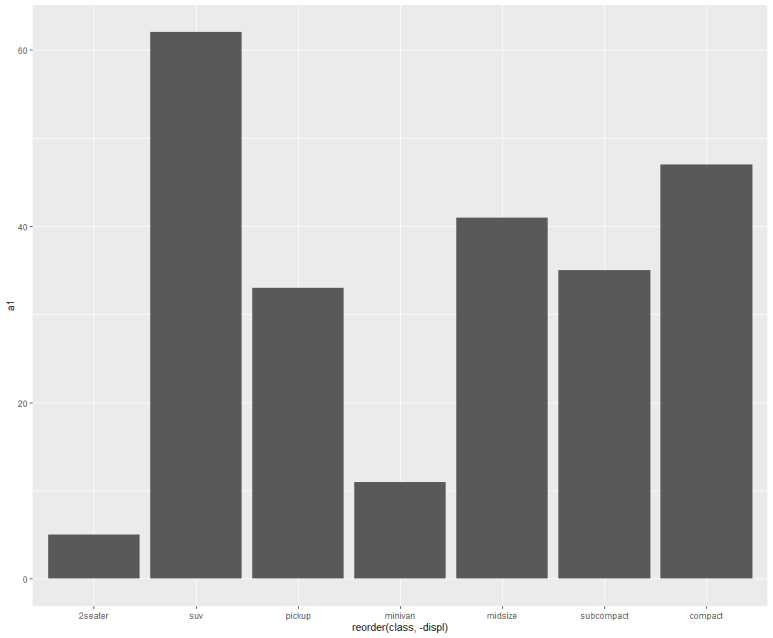
위와 같이, displ(배기량)이 가장 작은 compact, 가장 큰 2seater를 보면 각각 오름차순, 내림차순 그래프인 것을 알 수 있다 (평균 displ은 따로 구해보면, compact(준중형) 2.33, 2seater(스포츠카) 6.16이다)
여기서 의문이 들 수 있다. 그래프 크기와 전혀 상관없는 정렬이기 때문이다. 그 이유는 기준으로 입력한 displ 변수가 class별 카운트와는 전혀 무관한 변수이기 때문이다. 따라서, class별 누적 카운트값을 따로 명시해 이를 기준으로 정렬해보자.
먼저, 데이터 편집 라이브러리인 dplyr를 로딩한 다음, 아래와 같이 class_count 라는 열을 추가해보자.
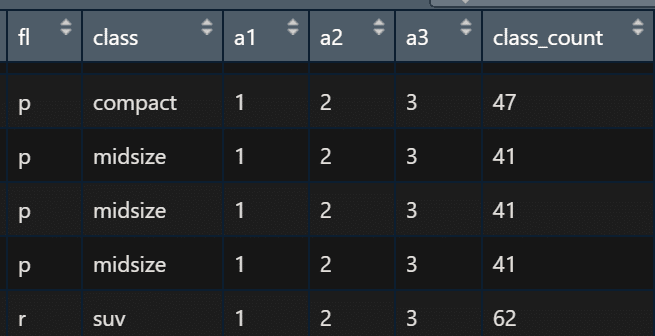
라이브러리 dplyr의 자세한 용법은 R 별도 섹션에서 따로 다룰 예정이므로, 간략히만 소개하면 group_by()함수를 통해 class를 기준으로 분류한 다음 각 분류한 데이터 별로 class_count라는 변수를 추가로 만들어(mutate) n() 즉, 각 행 수를 표시하라는 의미이다. 따라서, 위에서는 compact가 47개, midsize가 41개, suv가 62개 행이 존재함을 알 수 있다. 이제 아까 displ을 기준으로 정렬한 것처럼, class_count를 기준으로 정렬해보자.
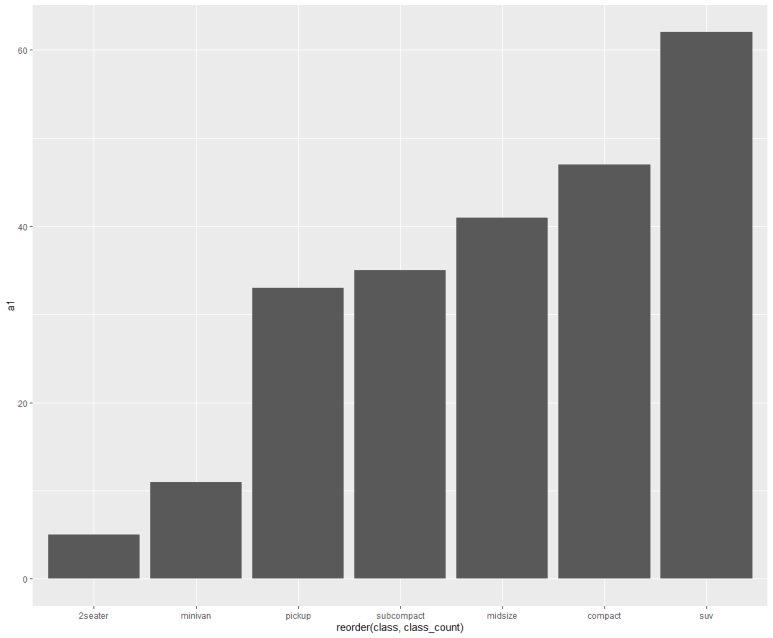
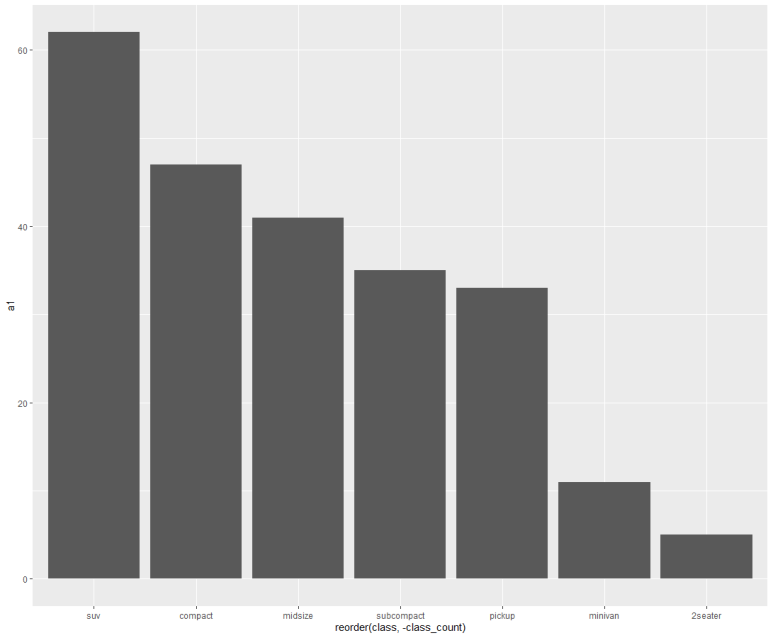
드디어, 막대그래프 크기 순으로 각각 오름차순/내림차순 표시가 되었다.
색깔 넣기
그러나 여기에서 끝내기에는 뭔가 아쉽다. 그렇다. 색깔이 흑백이다. 다채로운 색깔로 구분해서 표시하면 어떨까. 이럴 때는 aes() 안에 fill = 기준 변수를 추가하여 색깔을 칠한다(fill).

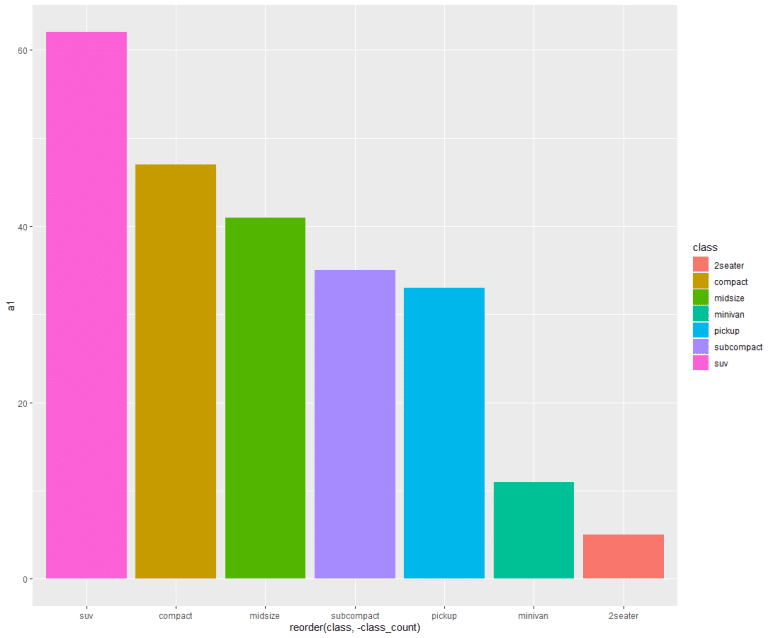
막대 누적 그래프
이제야 뭔가 있어보인다. 하지만 그래도 뭔가 좀 아쉬운 건 사실이다. 앞에서 geom_bar() 함수는 기본적으로 누적으로 표시한다고 하였는데, 이를 확실히 응용할 차례다. 막대별로 각 그룹(다른 변수)을 기준으로 구분해보자. 즉, 막대 누적그래프를 본격적으로 표시해본다. 방금 fill = (x축 변수)로 했기 때문에 x축 별로 구분된 것이고, fill = 옵션에 다른 변수를 입력하면 어떻게 되는지 보자.
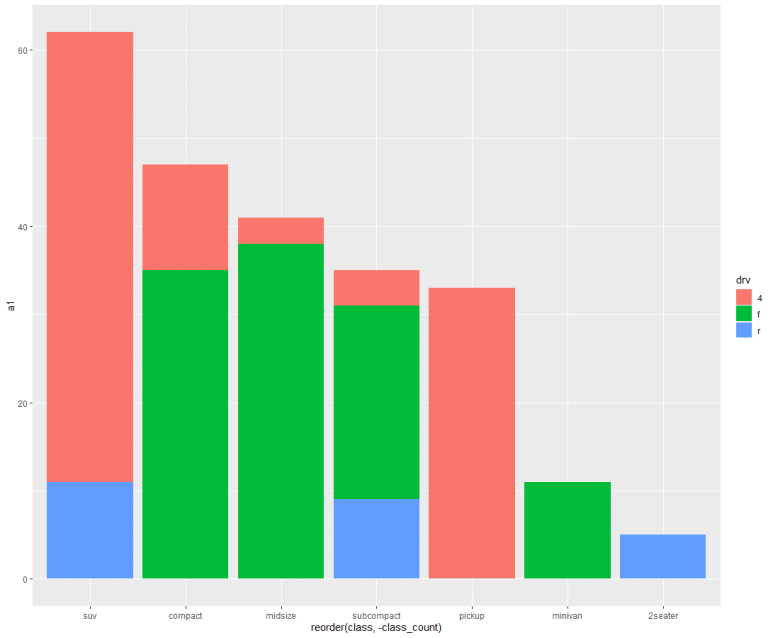
즉, 각각의 크기는 그대로인 채 각 막대그래프가 어떤 요소(fill 기준 변수)로 구성되는지 알 수 있게 되었다. fill 기준 변수로 입력한 drv(차량 구동방식)에 따라, suv 클래스 차량의 경우 4(4륜 구동), f(전륜 구동)으로만 구성되어 있고 r(후륜 구동)은 없음을 알 수 있다. 마찬가지로 2seater 클래스 차량의 경우는 모두 r(후륜 구동)으로 이루어져 있다.
자세한 설명을 위해 y축을 추가로 정해 코딩했지만, 사실 단순 count시에는 앞서 본 것처럼 x축만 정해도 된다. 유의할 점은, y축을 생략할 경우, stat = “identity”도 같이 생략해야 한다(아니면 stat = “count”로 변경). 아래 두 구문은 결과가 위 그래프와 동일하다.

지금까지 원본 mpg 데이터를 가지고 분석하였으나, 분석 대상인 변수가 일부에 한정된 경우에는 별도의 데이터셋을 만들어 이를 그래프화하는 것이, 예상치 못한 결과도 방지하고 가벼운 데이터를 통해 더 빠른 처리를 할 수도 있다.
따라서, 이번에는 mpg 데이터를 그대로 두고, 분석의 대상인 class 변수를 기준으로 별도의 데이터셋을 만들어본다. 여기 쓰인 count() 함수는 dplyr 라이브러리에 포함된 함수이므로 사용 전 라이브러리 로딩이 되어 있어야 한다.

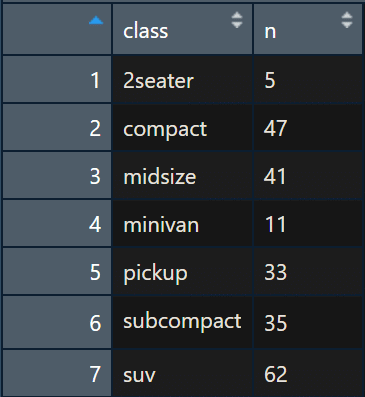
즉, count(데이터명, 카운트할 변수)로 실행하면, 변수와 n(해당 행 수) 2가지로 구성된 데이터 mpg2가 생성된다. 참고로 여러 변수를 동시에 만족하도록 카운트하고 싶다면 아래 같이 변수를 여러 개 입력하면 된다.

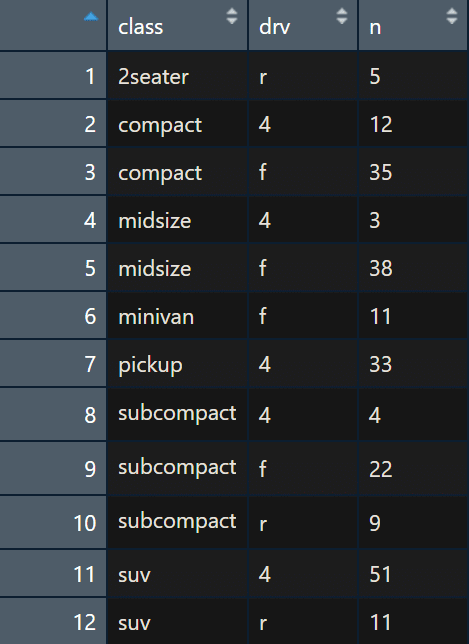
변수가 여러 개일 경우, 위의 경우처럼 class가 같더라도 drv가 다르면 별개로 보고 n의 값이 표시된다.
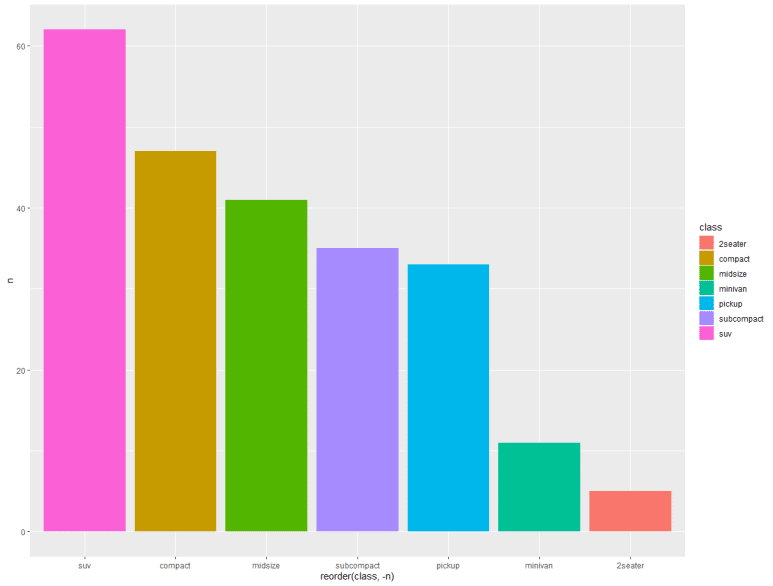
mpg2 데이터를 기준으로 기본 막대그래프를 먼저 그려보자.

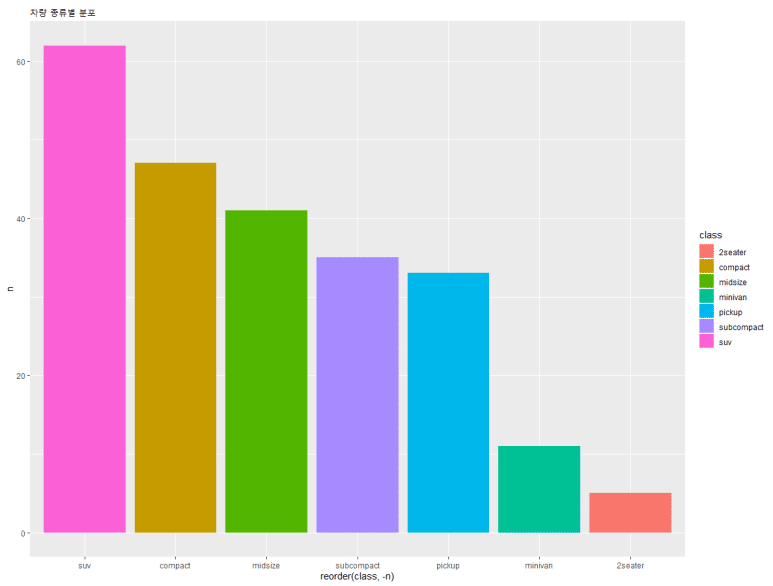
제목 넣기
그런데 가만히 보니 그럴싸한 제목이 따로 없다. 제3자가 보면 무슨 그래프인지 도통 알기 힘들 수가 있다. 이 때에는 ggtitle = 함수를 써서 친절하게 제목을 표시해주자.

제목을 추가했더니, 이번에는 x축 이름(reorder(class, -n))과 y축 이름(n)이 마음에 안 든다. x축 이름은 아예 없애고 y축 이름은 “차량 대수”로 바꿔보겠다. 각각 xlab(), ylab() 함수를 사용하면 된다.

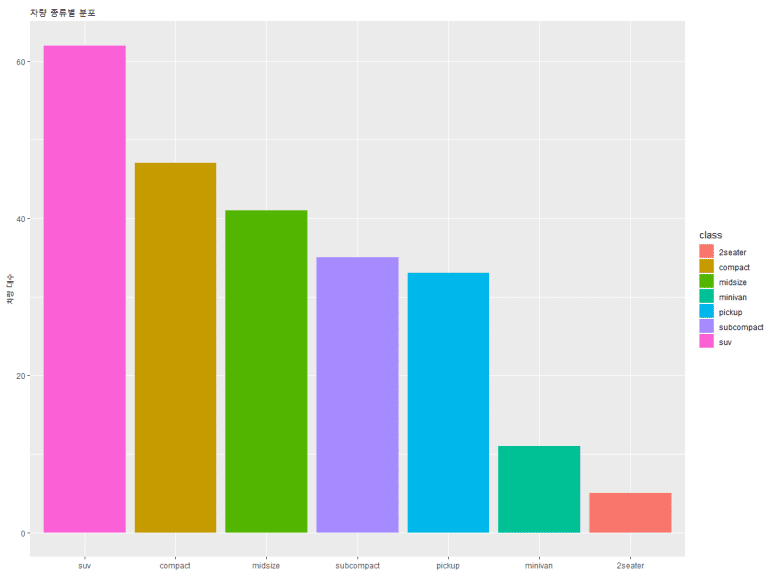
이번엔 막대 크기별 수치가 어떻게 되는지 불명확해 보이므로, 막대마다 수치를 표시해주고자 한다.

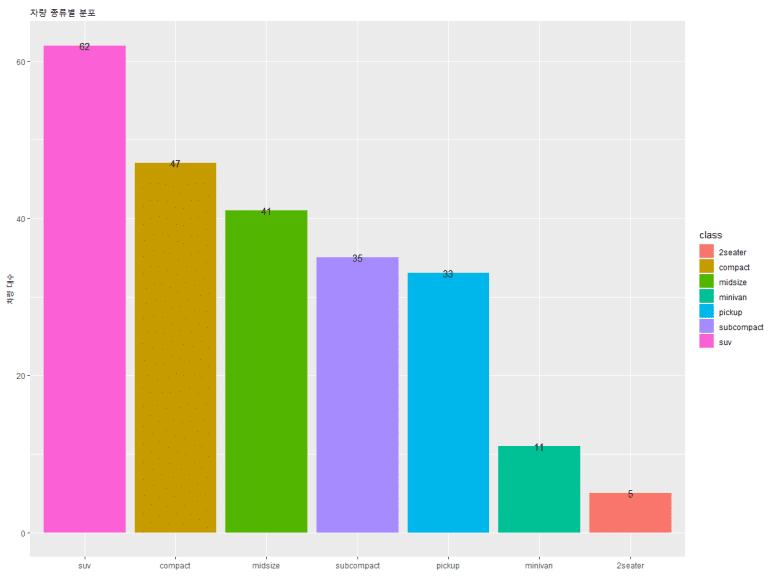
그런데, 숫자가 그래프와 겹쳐 가독성이 떨어진다. 위치를 조금 바꿔봤으면 좋겠는데… 그래서 준비했다. 바로 vjust =, hjust = 옵션이다. 각각 수직(vertical; 상/하), 수평(horizontal; 좌/우)를 의미한다.
값 기준 방향: 상(-) 하(+) 좌(+) 우(-)

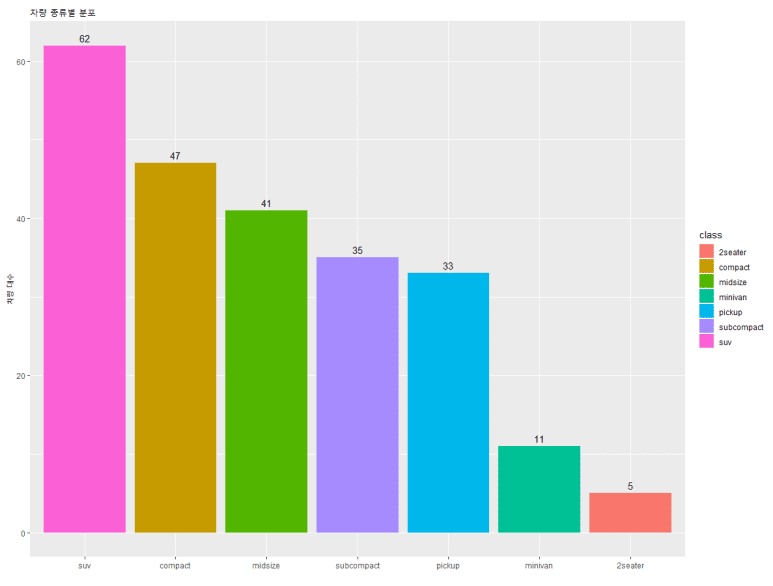
그런데, 숫자가 너무 작은 것 같다. size = 옵션을 추가해보자.

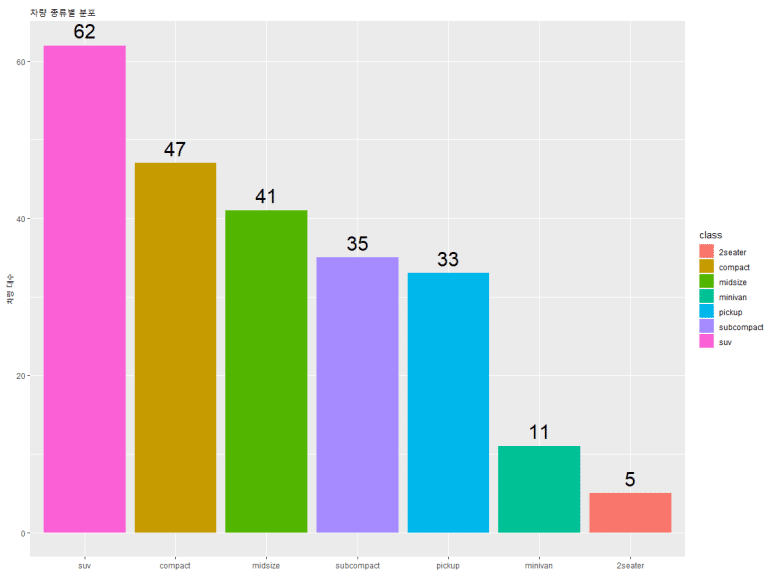
그런데 가만 보니, 오른쪽의 범례가 별로 필요없어 보인다. 어차피 x축 눈금에 표시가 되어있으니 말이다. 따라서 아래와 같이 추가적으로 테마 관련 구문을 작성해준다.

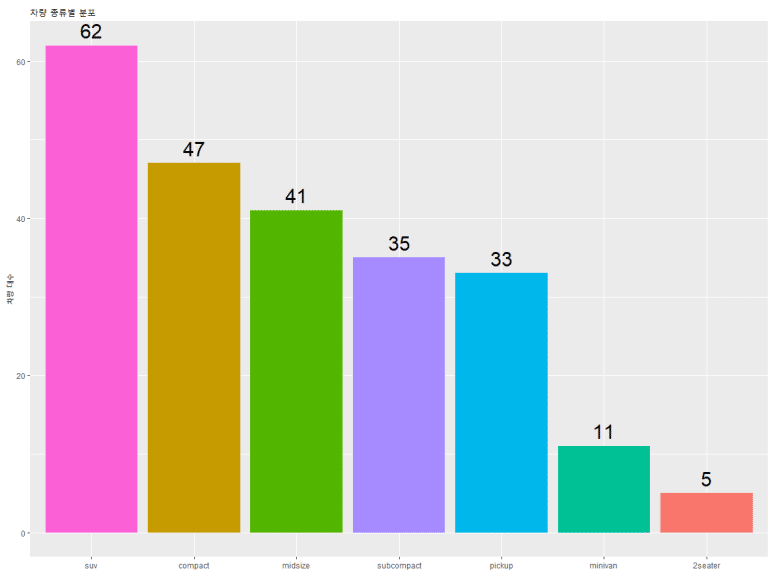
범례를 없앴더니, 그래프가 더 커 보이고 뭔가 효율적으로 변하였다. 참고로, 범례(legend)를 없애지 않고 위치만 바꾸려 한다면 theme(legend.position = “none”)에서 “none”를 “top”(위), “bottom”(아래), “left”(왼쪽), “right”(오른쪽)으로 변경하면 된다.
범례를 그렇다고 해서 상하좌우 지정된 위치로만 변경할 수는 있는 것은 아니고, 디테일하게 위치를 조정하는 것도 가능하다. 이럴 때에는, theme(legend.position = c( x축의 백분율 좌표, y축의 백분율 좌표 )를 사용한다. 즉, 그래프의 원점을 (0, 0)으로 보고 우측 상단 모서리를 (1, 1)로 하여 상대적 위치를 소수점으로 표현하면 된다.
여기에서는 우측 상단에 빈 공간이 많으므로 범례를 여기에 위치시켜 보겠다.
x축은 90%, y축은 85%쯤 되는 공간이면 theme(legend.position = c(0.9, 0.85)를 입력하면 된다.
주의할 점은, 위치 좌표는 범례 정가운데를 기준으로 한다 (다시 말해, 모서리 등으로 하면 일부 잘린다).

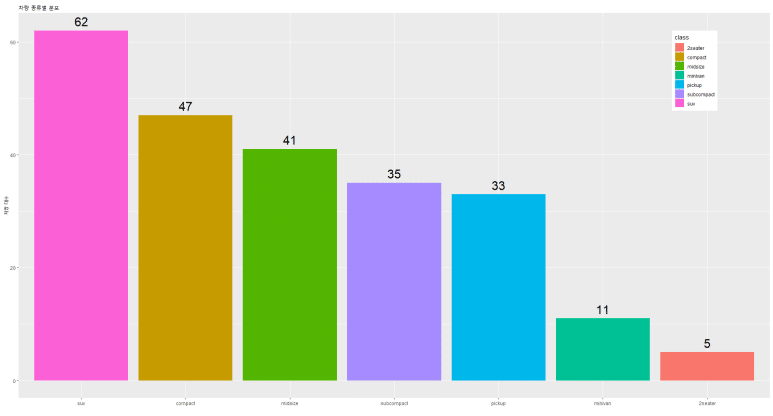
크기 변경
하지만 범례 텍스트가 작아보이는 것은 아쉽다. 텍스트 사이즈를 좀 더 키워보겠다.
범례 제목은 legend.title = element_text(size = 숫자) 형식으로 사이즈 조정이 가능하다.

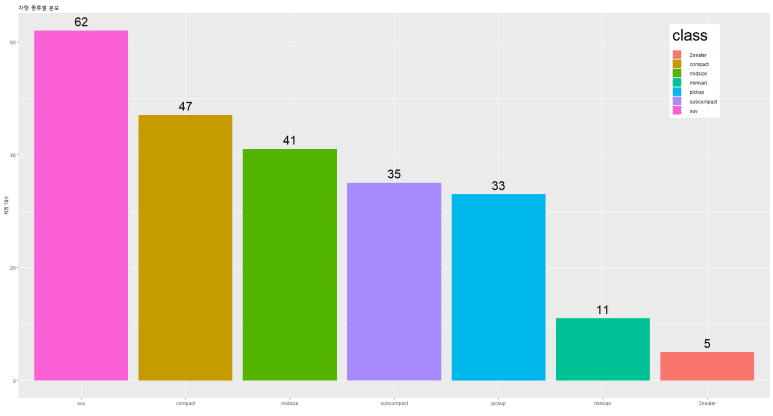
범례 제목은 크게 해 놨는데, 그 밑의 세부 항목들 글자가 너무 작다. 이것도 키워보자.
이 때는, legend.text = element_text(size = 숫자) 의 형식을 사용한다. 이쯤되면 계속해 legend 구문을 쓰는 이유가 궁금할 수 있는데, 범례가 영어로 legend 이기 때문이다.
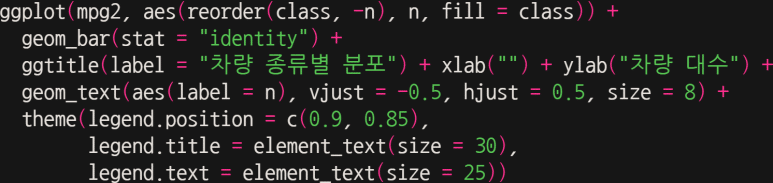
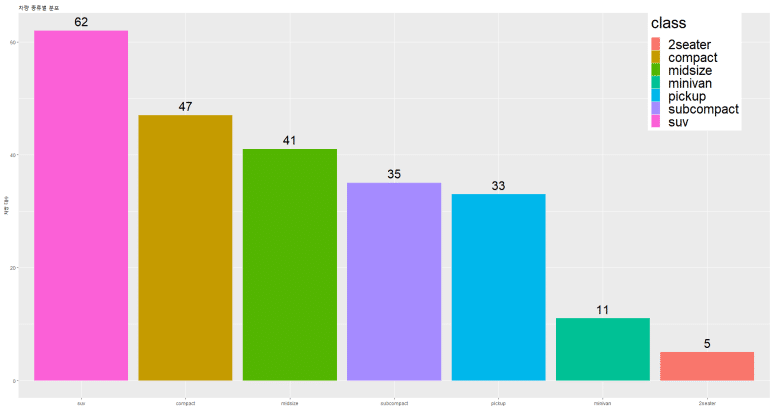
사람의 욕심은 끝이 없는 것일까? 제목이 너무 작다. 사이즈를 더 키워보자. 이제부터 모든 텍스트 크기는 theme() 함수에 입력하기로 한다.

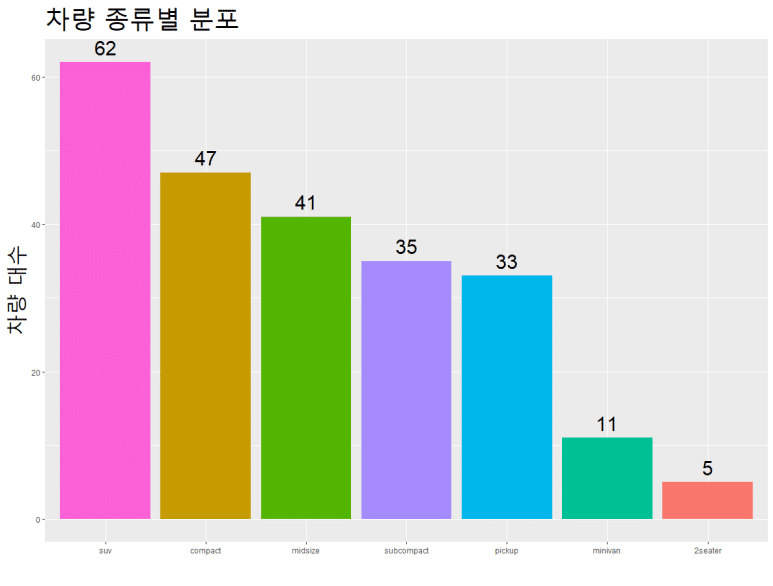
기왕 하는 김에 x축 눈금(axis.text.x)과 y축 눈금(axis.text.y) 텍스트 사이즈도 바꿔보면 어떨까?
또, x축 눈금의 텍스트는 특별히 굵게(“bold”) 표시해보자.

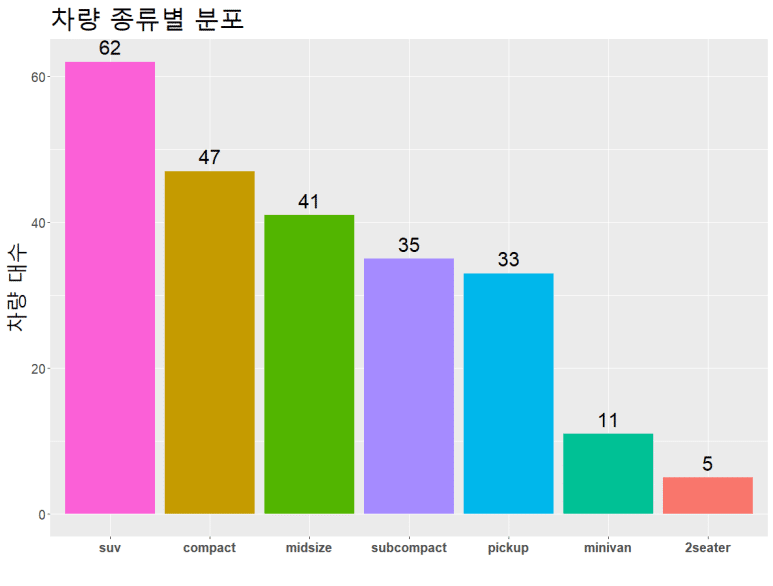
강조하기(annotate)
여기까지 따라왔다면, 지쳤을 수 있지만 이 정도만 해도 ggplot의 실무적 활용에 큰 어려움은 없을 것이다.
정말 마지막으로 강조 구문(annotate)을 첨부하고 ggplot 기초를 마칠까 한다.
(annotate 용법은 매우 다양하고, 이 중 하나를 예시한 것이다)
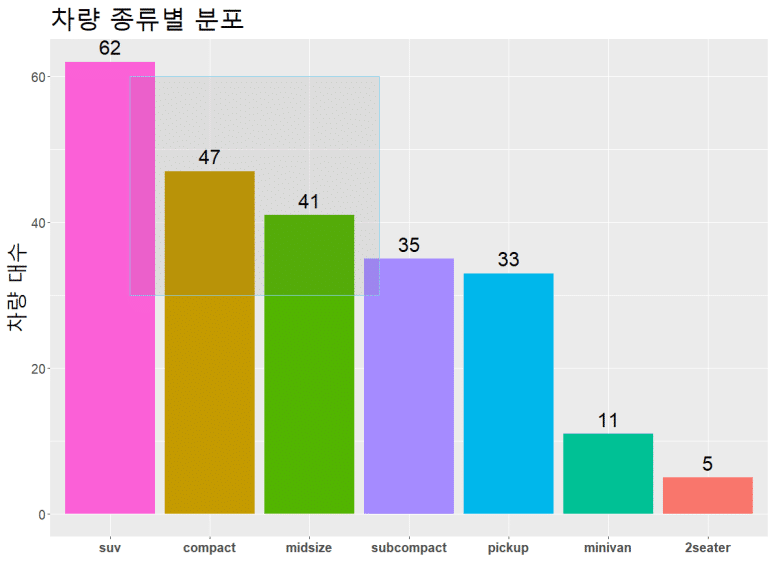
가로 그래프
정말 마지막으로.. coord_flip() 함수를 추가해 그래프를 가로 방향으로 변형해보고 끝마친다.
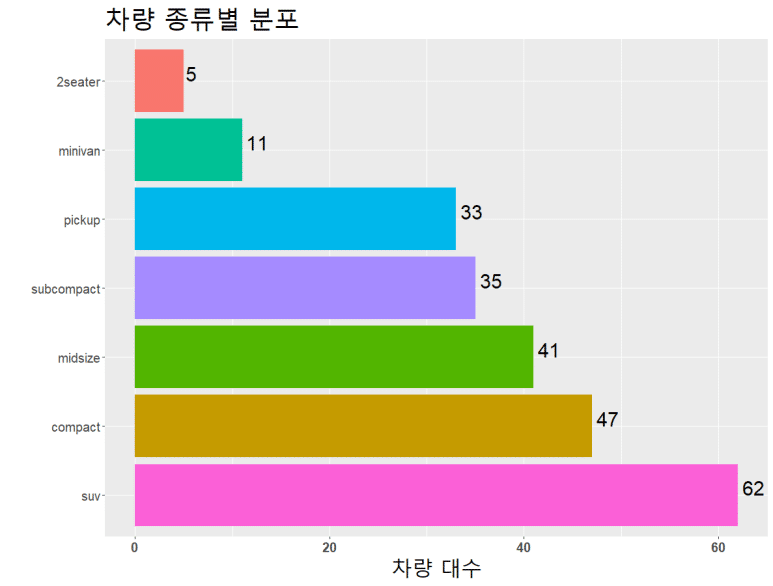
축 지정
하지만, 마지막은 또 다른 시작을 의미한다. 이번에는 y축을 지정하는 법에 대하여 배워보자 (x축도 가능).
y축 그래프가 20 단위로 자동 스케일링되어 있는데, 이를 10 단위로 바꾸려면 어찌 해야할까?
이 때에는, scale_y_continuous() 함수를 사용하면 된다 (x축은 scale_x_continuous() 함수 사용)
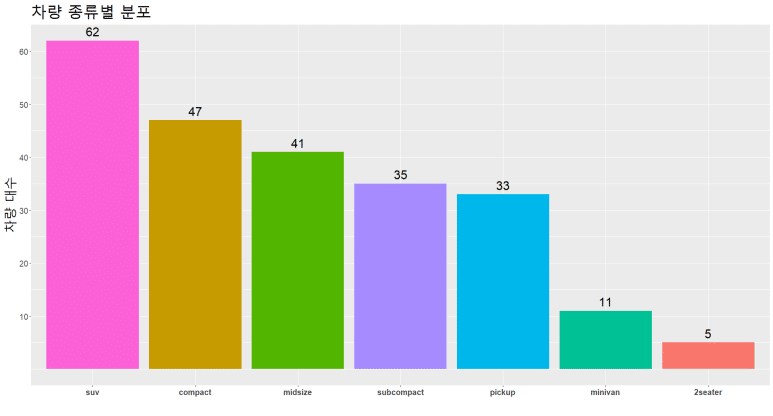
그런데, y축 눈금을 c(10, 20, 30, 40, 50, 60)으로 가내수공업처럼 일일이 한땀 한땀 장인정신으로 꾹꾹 누르고 있기엔 인생이 너무 짧다. 이 때에는 시퀀스 함수 seq(시작 숫자, 끝 숫자, by = 간격)을 사용하자. 여기서 by = 은 생략 가능하다. 특별히 시작 숫자를 5, 간격도 5로 해 본다.
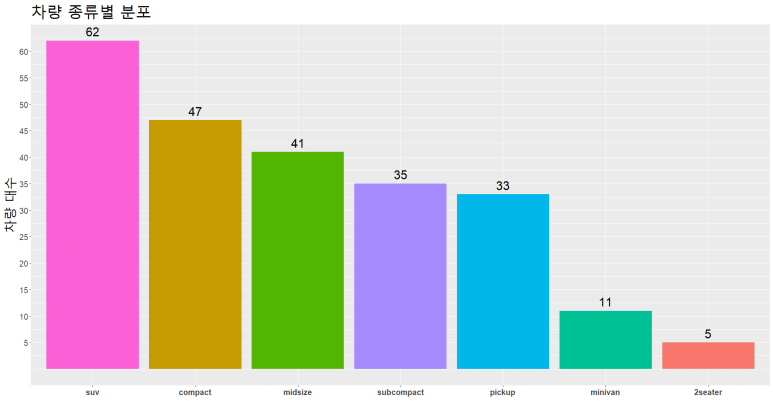
만약, y축 눈금 단위가 1,000이 넘는다면 별도의 지정없이는, 1000 2000 3000 처럼 백단위로 콤마(,)가 생략되어 표시될 것이다. 이 때에는 scale_y_continuous(labels = scales::comma, breaks = seq(10, 60, 5)) 처럼 별도 comma 구문을 사용하면 해결된다. 여기서 scales::comma 라 한 이유는, comma 함수를 사용하기 위해 scales 라이브러리가 필요하다는 뜻이고, 사전 scales 라이브러리를 로딩한 상태라면, labels = comma로 입력해도 된다.
이번엔 약간 디자인 감각을 살려 그래프가 너무 두꺼우니, 좀 가는 막대그래프로 바꿔보고자 한다. ggplot() 안에 옵션으로 width = 를 사용해보자.
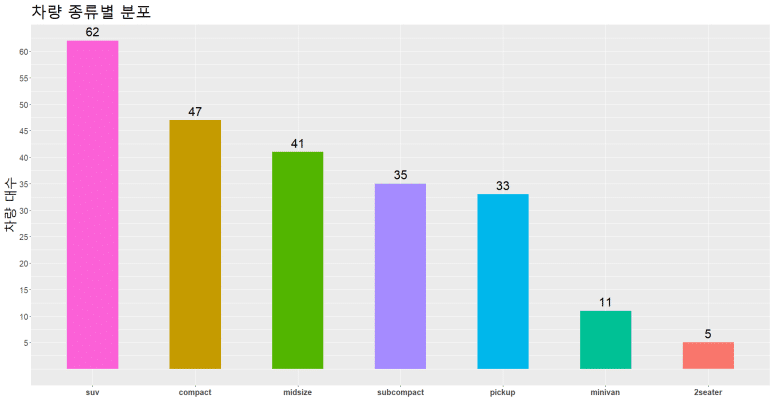
이번에도 coord_flip() 함수를 써 가로본능으로 돌려보자.
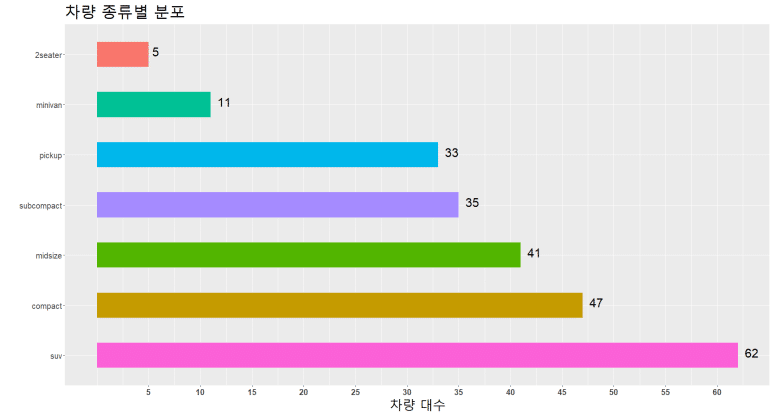
원 그래프
수치는 정확한데, 뭔가 심심하다. coord_flip() 말고, 원 그래프 그리는 coord_polar()를 써 보면 어떨까.
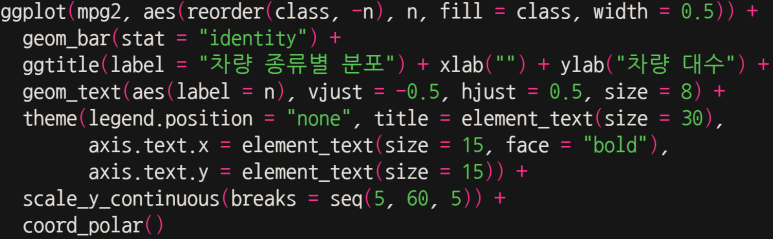
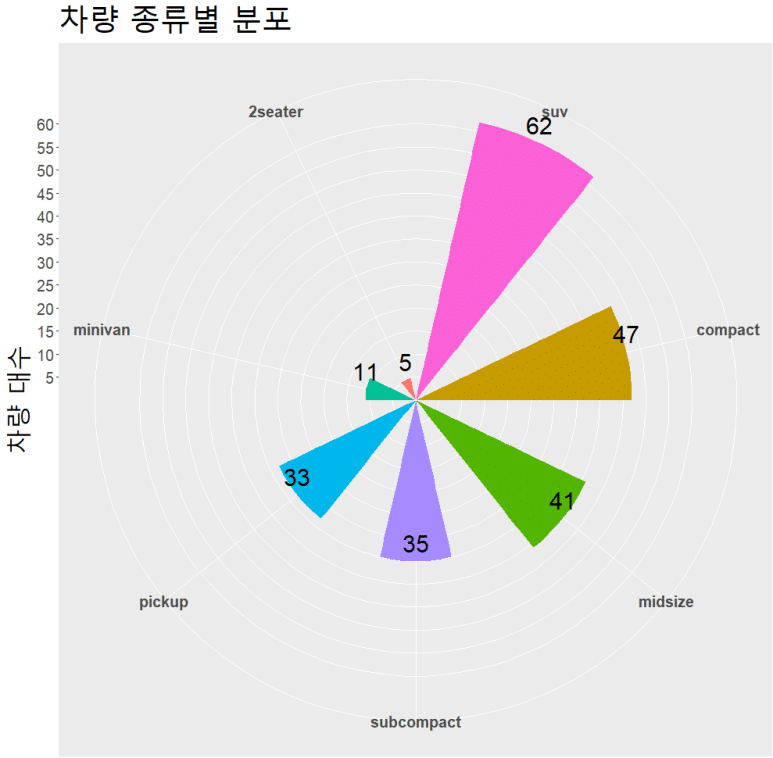
… 별로다.