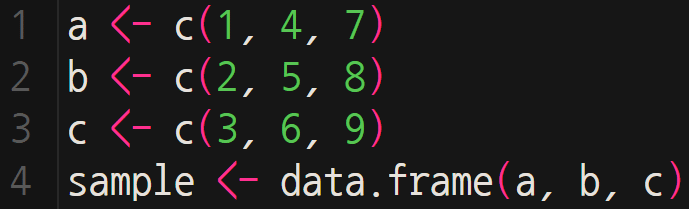
RStudio를 실행하여 위와 같이 샘플 데이터를 생성해보자.
여기서 굳이 a <- c(1, 2, 3) 이라 하지 않은 것은, a 가 ‘열’을 의미하기 때문이다 (행이 아님).
마지막 줄 sample <- data.frame(a, b, c)는 각 a, b, c라는 이름으로 생성된 1차원 벡터를 2차원 데이터프레임으로 만드는 명령어로서, 흔히 활용하는 엑셀의 셀 모양을 떠올리면 된다 (가장 많이 쓰이는 데이터 형태 -소위 직사각형 데이터).
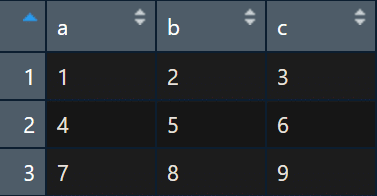
즉, 지금 생성하고자 하는 샘플 데이터 형식은 아래와 같다.
사실, 위 4행 명령어는 한 줄 작성도 가능하다.
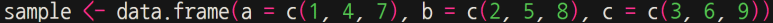
결과는 물론 같다.
하지만, 과정에서의 차이는 있다. 즉, 위와 같이 한 줄로 작성할 경우, a, b, c 각각의 벡터 생성은 생략된다.
다시 말해, 메모리에 sample이라는 데이터만 저장되고, 별도 a, b, c 라는 독립 데이터는 따로 저장되지 않는다.
무엇이 좋고 나쁜지의 차이는 case by case다. 즉, a, b, c 라는 벡터를 이후 또 활용하지 않을 것이라면 한 줄이 간결할 수 있다. 다만, a, b, c라는 벡터를 이후에도 자주 활용할 예정이라면 따로 생성하는 것이 편하다.
다시 말해, a 데이터에 대해 각각 1을 더한 수를 알고 싶다 할 때, a가 메모리에 저장되어 있다면 그냥 a+1을 하면 되지만, 별도 저장되지 않은 상태라면 일일이 다시 적어줘야 한다.
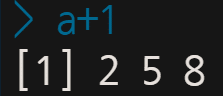

사실 큰 차이가 없고 또 크게 번거롭지 않은 일이라 보일 수 있다.
하지만 코드가 길어지고, 사용 변수가 많아질수록 어떻게 코딩하냐에 따라 추후 유지보수 등 활용성에 차이가 많으므로 자주 활용되는 변수인지 항상 생각하고 전개해나가야 한다.
데이터명[ ] 문법
이는 데이터를 한 level씩 내려가며 본다고 생각하면 이해가 빠르다.
즉, 데이터만 놓고 보면 (데이터프레임의 경우) 2차원 행과 열이 기본 표시되는 반면, [ ]를 바로 붙여서 쓰면 해당 부분만 추출된다.

이 결과는 아래와 같다.

먼저 sample[2] 는 두 번째(2) 열인 b를 나타낸다.
sample[3]을 쓴다면 당연히 세 번째 열인 c가 나타날 것이다.
만약 sample[[2]]처럼 중첩해서 사용한다면, b가 데이터프레임 부분으로서 ‘열’로 나타났던 것이 이제는 데이터프레임 형태가 아닌, b 자체가 ‘벡터’로서 추출된다.
(즉, 데이터구조 level이 더 저차원화 되었다고 생각하면 이해가 빠를 것이다)
이는, sample$b를 통해 직접 확인한 것과 결과가 같다.
그럼 열 단위가 아닌 행 단위 표시는 안되는 것인가? 물론 할 수 있다.
사실 sample[2]는 sample[,2]라고 입력한 것과 결과가 같다.
반대로 말하면, sample[2,]로 표시할 경우는 두 번째 ‘열’이 아닌, 두 번째 ‘행’이 호출된다.
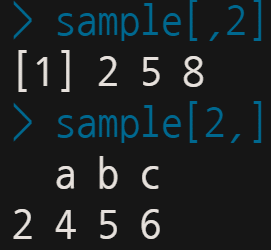
자, 그럼 이번에는 sample[행, 열]을 다 써주면 어떻게 추출될까?
물론 생각한 바와 같다.

이번에는 각 행, 열 앞에 마이너스(-) 부호를 붙여보자. 코딩에 있어 마이너스(-)부호는 보통 붙이기 전과 반대로 작용함을 의미한다. 그렇다. 이번에는 해당 행과 열이 생략되고 나머지가 추출될 것이다.
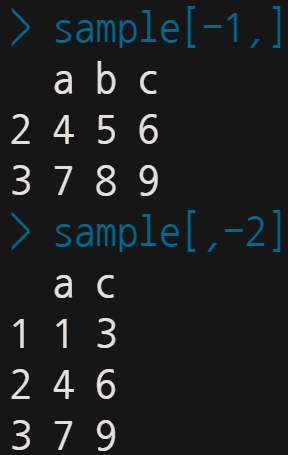
이를 응용하면 다음과 같이 될 것이다.
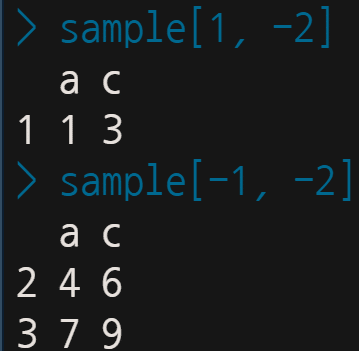
사실 지금까지 배운 것이 별로 유용하게 보이지 않을 수 있다.
또, 나중에 배울 라이브러리를 통해 같은 결과를 구현할 수 있기도 하다.
하지만, 이 기초 문법은 R 프로그램 자체 내장된 함수로 특정 라이브러리가 없이도 작동이 되고, 빠른 속도로 처리되는 장점이 있다.
기초가 튼튼해야 그에 따른 응용 범위도 훨씬 커지는 법이다.