kaggle 소개
전세계 데이터 사이언티스트들에게 가장 Hot한 웹사이트를 꼽으라면, 대부분 kaggle을 꼽을 것이다.
왜냐하면, 빅데이터 분석을 하고자 할 때 가장 첫 번째 단계는 바로 데이터를 구하는 것인데, 사실 직접적인 이해관계자가 아니라면 쉽게 구할 수 없는 것이 ‘데이터’이기 때문이다.
바로 이러한 점을 해결하고자, 마치 오픈소스를 공유하는 것처럼 각 기관/기업/개인이 무료로 데이터들을 공유하는 곳이 여기, ‘캐글(kaggle)’이다.
캐글(kaggle) 웹사이트 주소는 아래와 같다.
웹사이트 내 정보를 이용하려면, 먼저 회원가입을 필요로 하는데, 구글, 페이스북 등 기존에 가입되어 있는 타 사이트의 정보를 연동해 가입도 가능하므로 비교적 쉽게 할 수 있다.
왼쪽을 보면 여러가지 메뉴가 있는데, Competitions는 기업이 자사 이익 목적으로 데이터를 공개하여 분석을 경쟁시키는 곳이다. 물론, 그 기업의 데이터를 가장 잘 분석한 사람에게는 해당 기업이 정한 상금을 수여한다. 아무래도 실력이 높은 사람들이 많을 수 밖에 없다.
그리고, 그 아래의 Datasets는 특정 목적이 있다기보다는 각 회원들이 쓸모있다 생각하는 데이터셋들을 공유하기 위해 업로드하는 곳이다. 우리가 주로 이용할 메뉴다.
그 아래의 Code, Discussions 등은 해당 데이터를 분석한 코딩 내용 및 의견 교환 등을 목적으로 개설된 메뉴로서, Dataset 등 다른 메뉴를 통해서도 접근 가능한 하위 메뉴라고 보면 된다.
데이터셋 찾기
이제 분석할 데이터셋을 찾아보자.
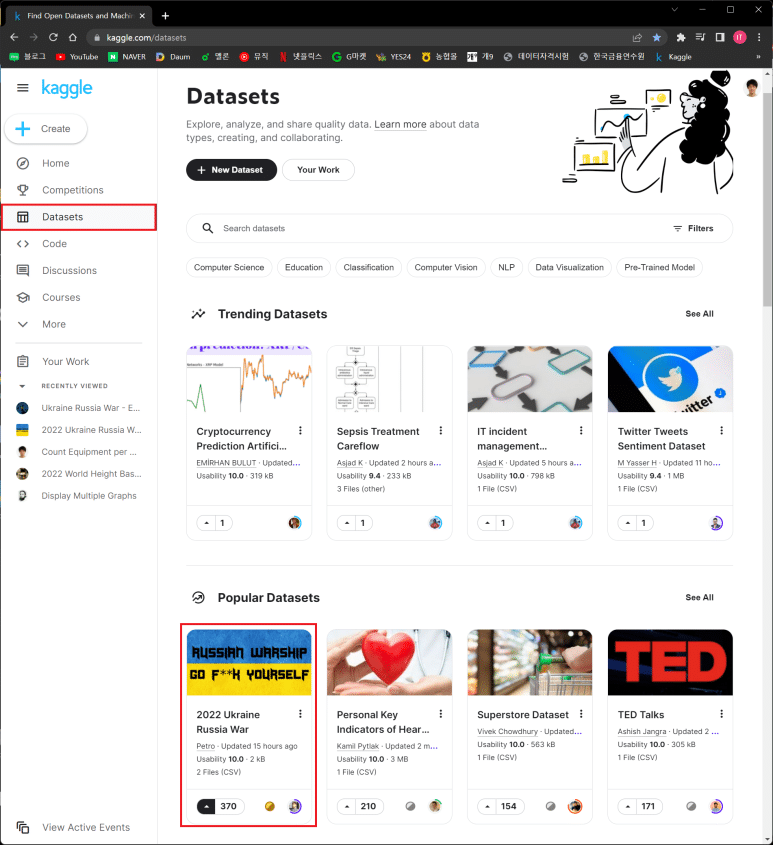
요즘 가장 인기있는 데이터셋 랭킹 목록에 ‘2022 Ukraine Russia War’가 떠 있는 것을 볼 수 있다.
그 밑에 370 이라는 숫자는, 회원들이 누른 일종의 ‘좋아요(Like)’ 숫자라고 보면 된다.
2022 Ukraine Russia War 데이터셋에 대한 설명은 아래와 같다.
About Dataset
44 day of WAR
This is the dataset that describes Equipment Losses & Death Toll & Military Wounded & Prisoner of War of russians in 2022 Ukraine russia War.
All data are official and additionally structured by myself.
A lot of civilians and children have already been killed by russia troops. Ukraine is in war flame and under missile attack now. We are strong. Stand with Ukraine. #StandWithUkraine, @StandWithUkraine
Important. Each new record is accumulated data from previous days.
Important. Data will be updated daily
Data Sources
Main data sources are Armed Forces of Ukraine and Ministry of Defence of Ukraine. They gathered data from different points of the country. The calculation is complicated by the high intensity of hostilities.
Invaders – Russians Prisoner of War (POW).
Oryxspioenkop – Ukraine and russia Equipment Losses. This list only includes destroyed vehicles and equipment of which photo or videographic evidence is available. Therefore, the amount of equipment destroyed is significantly higher than recorded here.
Liveuamap – Live Interactive Map with events that happened.
Live monitoring of all sanctions against Russia – Correctiv.
Tracking sanctions against Russia – Reuters.
Russia’s Attacks on Civilian Targets Have Obliterated Everyday Life in Ukraine – NYTimes.
Help to stop Russian war against Ukraine – Kaggle Petition.
Dataset Social Media Athletes from russia & belarus – Social Media of russia and belarus athletes that took part in Beijing 2022 Olympic Winter Games.
Dataset in JSON format – The same data on Github.
Tracking
Personnel
Prisoner of War
Armored Personnel Carrier
Multiple Rocket Launcher
Aircraft
Anti-aircraft warfare
Drone
Field Artillery
Fuel Tank
Helicopter
Military Auto
Naval Ship
Tank
Acronyms
POW – Prisoner of War,
MRL – Multiple Rocket Launcher,
APC – Armored Personnel Carrier,
SRBM – Short-range ballistic missile,
drones: UAV – Unmanned Aerial Vehicle, RPA – Remotely Piloted Vehicle.
Dataset History
2022-03-02 – dataset is created (after 7 days of the War).
우크라이나-러시아 전쟁이 지속되고 있어, 데이터셋도 매일 갱신해서 올리고 있다는 설명이다.
여기 올라오는 자료는 전쟁 개시 시점부터 매일 해당 숫자를 누적해서 카운트하고 있는데,
이를 일일 변수로 다시 카운트해서 변화 추이를 알아보고자 한다 (누적 값 -> 일일 단위 변환).
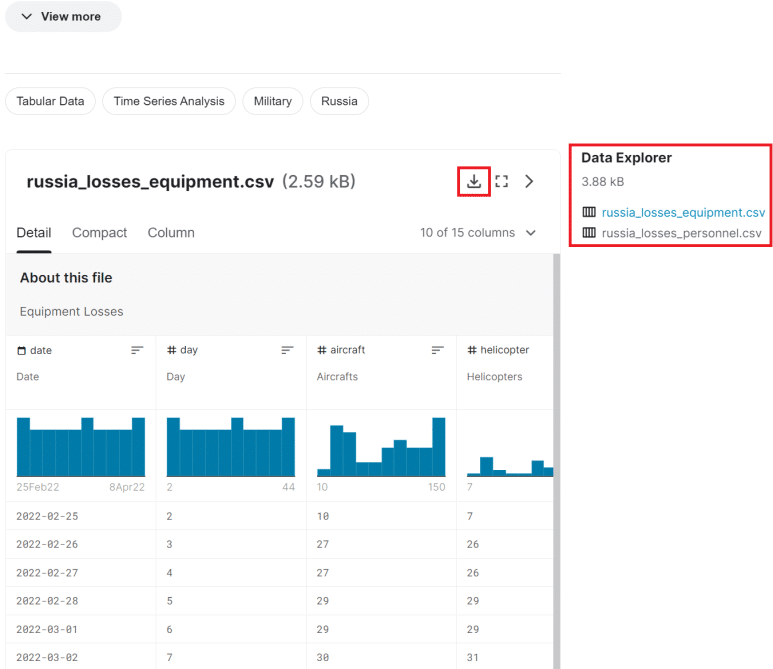
오른쪽을 보면 해당 데이터셋에 대한 파일 목록이 나와 있고, 각 파일을 클릭하면 해당 파일에 대한 설명이 나온다.
이 중 russia_losses_equipment.csv를 분석하고자 하는데, 아래에서 다운로드하면 된다.
보통 데이터셋 파일은 CSV (Comma Seperated Values) 파일이라 하여, 각 값들이 콤마(,)로 구분된 범용적인 데이터 파일 형태를 띠고 있다.
데이터 전처리
따라서 다양한 응용프로그램들로 불러오기할 수 있는데, 엑셀로 읽으면 아래와 같이 나타난다.
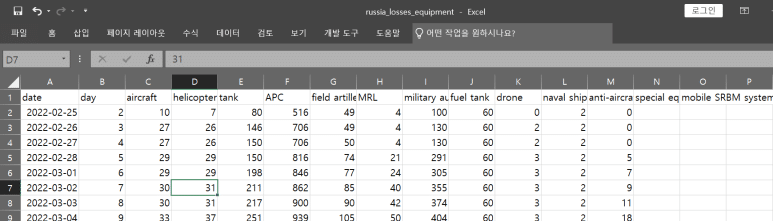
데이터는 구했으니, 분석을 시작해보도록 하자.
(Kaggle 내 New Notebook 클릭하여, Jupyter Notebook 형태 R / Python 코딩도 온라인 상 가능)
먼저 분석에 필요한 라이브러리를 로딩한다.
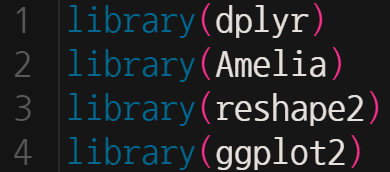
데이터 편집에 필요한 dplyr,
필수적인 것은 아니지만 결측치(NA)를 빠르게 찾을 때 필요한 Amelia,
특정 변수를 기준으로 데이터를 재정렬할 때 필요한 reshape2,
그래프로 표현할 때 필요한 ggplot2
raw 데이터셋으로 로딩할 russia_losses_equipment.csv 파일은 각자에 맞는 폴더 위치로 수정 사용.

다음은 같은 데이터를 가지고 여러 조건들을 기준으로 간편하게 분석할 수 있게, 변수를 선언하고자 한다.
물론 해당없이 데이터 검색하려면, 앞에 주석 표시인 #을 붙이면 된다 (주석으로 처리하면 실제 실행되지 않음). 일단 모두 앞에 #표시를 해 두었다.
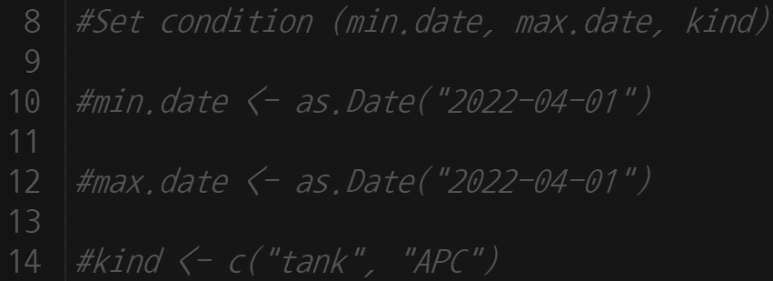
데이터 습득 후의 첫 단계, 변수별 속성을 알아보자.
콘솔 창에서 str(raw)을 입력하면, 아래와 같이 나타난다.
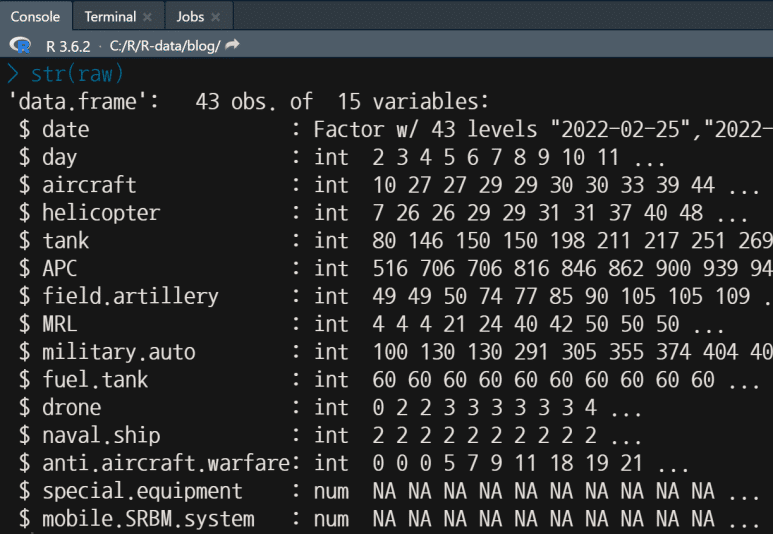
date가 Factor로 되어 있는 것 외에는 모두 숫자형 값으로 되어 있어 적절해보인다.
따라서 date 변수만 아래와 같이 날짜 속성으로 변환해준다.
그리고 나중에 원본과의 비교를 위해, raw1 이라는 데이터셋 사본을 따로 생성해 분석하고자 한다.
다음으로, 결측치(엑셀에서는 빈 칸, R에서는 NA로 표시되는 값)를 찾아보자.
raw1 데이터프레임을 직접 클릭하여 NA값 여부를 확인해도 무방하다.

하지만, 자료가 방대한 경우는 찾기 힘들 때도 있는데 이 때는 Amelia 라이브러리 missmap 함수를 쓰면 된다. missmap(raw1)을 실행하면 다음과 같이 표시된다.
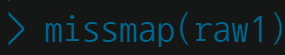
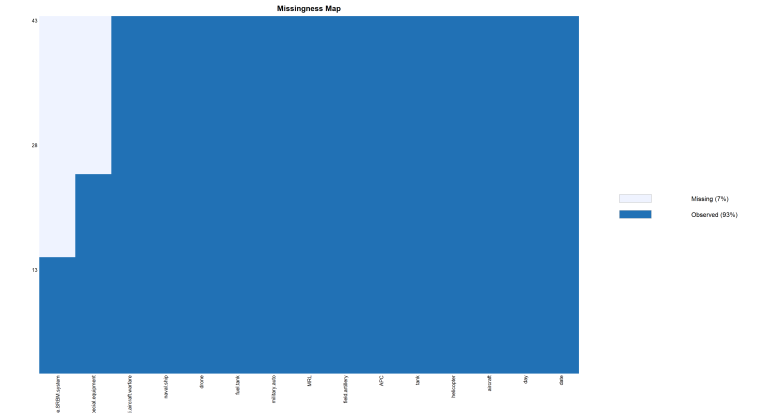
즉, 데이터셋 관측치(행) 총 43개 중 결측치(Missing Value, NA) 분포를 변수(열)별 표현한 그래프이다.
이를 보면, special.equipment, mobile.SRBM.system 두 개 변수에 NA가 포함된 것을 알 수 있다.
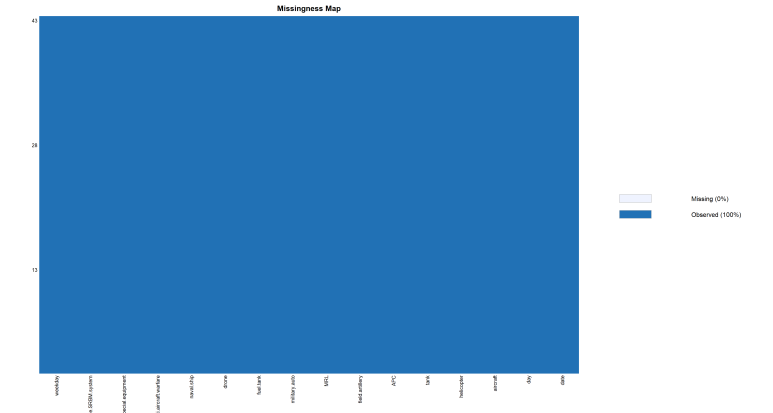
이를 그대로 두면, 나중에 연산 작업할 때 에러가 날 수 있으므로 두 변수의 NA를 0으로 미리 바꿔놓자.

그리고 다시 확인하면 NA값들이 모두 0으로 바뀌어 있는 것을 확인할 수 있다.

자, 이제 본격적으로 각각의 누적값을 일일 단위로 재계산하고자 한다.
그러기 위해서는 D+2일의 누적값에서 D+1일의 누적값을 빼서, D+2일만의 순증값을 구하면 될 것이다.
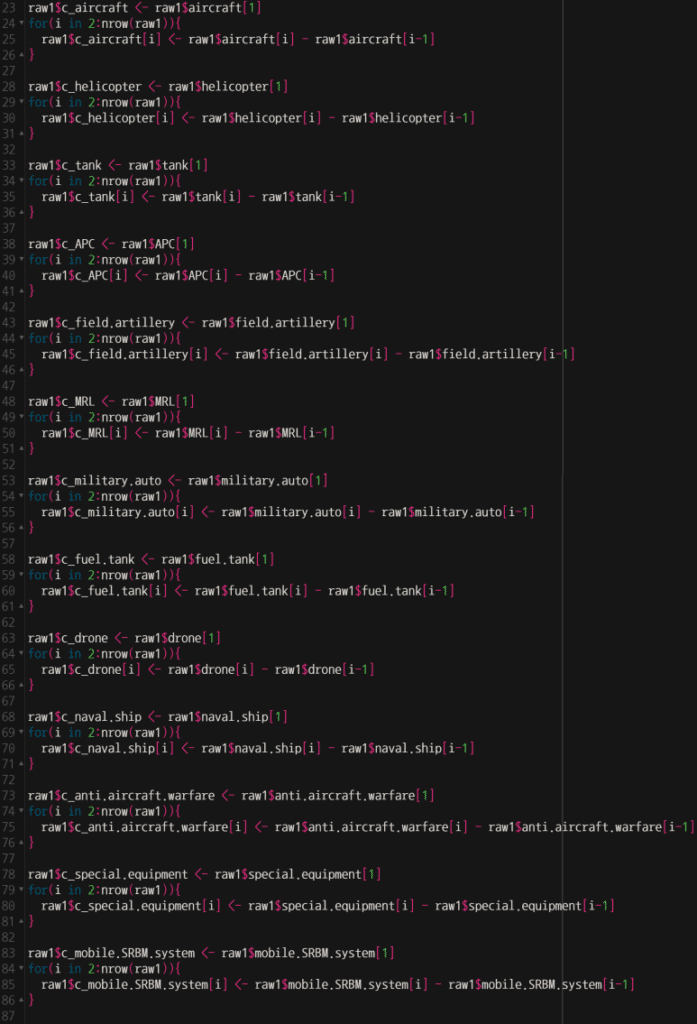
aircraft(항공기)의 일일 값을 구할 경우, 다음과 같이 하면 된다.

먼저 raw1$aircraft[1] 즉, aircraft의 첫번째 값으로 c_aircraft 열을 생성한 다음 for 반복구문으로 c_aircraft 열의 2번째 행부터는 로직을 통해 자동 생성되게 한다. 여기서 for(i in 2:nrow(raw1))의 의미는, i를 2부터 nrow(raw1) 즉, raw1 관측치 수(행 수)인 43에 이르도록 1씩 증가하며 대입, 반복하는 것을 의미한다.
이런 식으로 모든 변수에 대해 ‘c_변수명’을 생성해보자.
다음은, 앞서에서의 변수들이 존재(exists)할 때 어떻게 처리할지를 if 조건문으로 나타내준다.
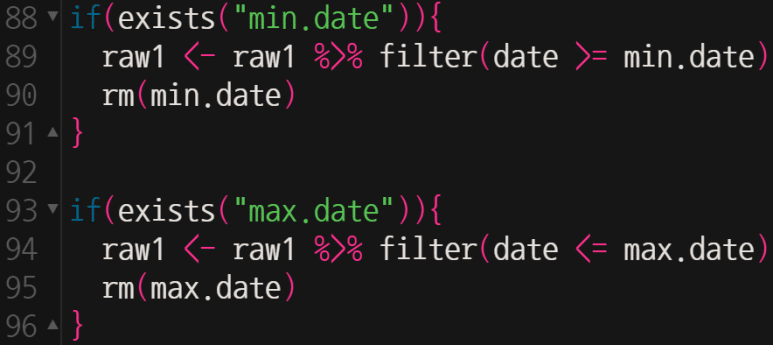
먼저 주석(#) 처리했던 min.date, max.date가 만약 선언이 되어 존재하고 있다면, min.date 날짜보다 늦은 date 관측치를 추출하고 동시에 max.date 날짜 이전인 date 관측치를 추출하겠다는 의미다. 이 때, if 조건문에 의해 두 변수 중 하나만, 혹은 둘 다 존재하거나 존재하지 않아도 에러는 발생하지 않는다.
이어서 rm명령어를 통해 바로 min.date, max.date 변수들을 삭제하는 것은, 조건 변경 후 재실행할 때 각 변수가 계속 존재(exists)함에 따라 오작동함을 사전에 방지하기 위함이다.
위에서 선언한 변수와는 별개로, 나중에 출력될 그래프의 제목으로 쓰기 위해, 주어진 자료의 “실제” 가장 빠르고 늦은 날짜를 따로 저장한다.

다음은 weekdays 함수를 사용하여 date 기준 요일을 weekday 열로 추가해주자.
(여기서 weekdays 함수는 우리나라에서는 한글로, 영미권에서는 영어(ex. Friday)로 자동 생성됨)
다만, R 내장 함수인 substr 사용해 첫째 자리부터 첫째 자리까지만 추출하였다 (ex. 금요일 → 금)
만약 ‘금요일’을 셋째 자리인 ‘금요일’로 모두 표시하게 하려면, substr(weekdays(raw1$date), 1, 3)로 마지막 숫자를 3으로 고치면 될 것이다.

date열도 마찬가지로 substr 함수를 사용하여 여섯째 자리부터 열째 자리까지만 추출해 갱신한다.
즉, 2022-04-08 중 앞에 다섯째 자리(2022-)를 제외하고 04-08만 표시하게 한다는 것이다.
(이유는, 시계열 그래프 표현할 때 x축 날짜 표기를 간소화하여 가독성을 높이기 위함)
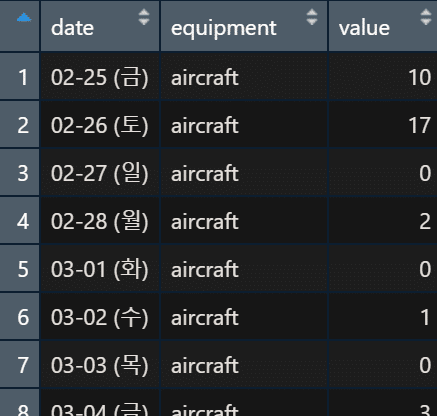
그리고나서, date와 weekday를 paste0 함수로 합쳐 ’22-04-08 (금요일)’과 같이 표시되도록 date를 갱신한다.
이제 일일 순증값인 c_ 함수들을 모두 생성했으니, 기존 누적값들은 필요가 없다. 따라서, 날짜(date) 열과 순증값(c_로 시작하는 변수) 열만을 추출하겠다. 여기서 starts_with(“c_”)는 c_로 시작하는 모든 열을 의미하는데, 이러한 용법의 자세한 설명은 본 블로그의 ‘R 데이터 핸들링’ 편을 참조하기 바란다.

여기서 names(raw1)는 raw1 데이터프레임의 모든 열 이름을 의미하고, 위와 같이 R 내장 함수 gsub를 이용하여 일괄 변경한다. ☞ 용법: gsub(“기존 글자”, “바꿀 문자”, 대상 데이터)
이 데이터셋을 그대로 그래프화할 수는 있으나, 날짜를 중심으로 모든 데이터를 핸들링하고자 할 때에는 재정렬해서 사용하는 게 편하다.

라이브러리 reshape2에서 제공하는 melt 함수를 활용, date열 기준으로 하여 모든 변수를 value 값으로 일괄 정렬한다.
이 때, date 이외의 모든 변수(열)는 variable이라는 하나의 새로운 변수로 정렬되는데, 알기 쉽게 variable 변수(열)는 equipment 변수(열)로 이름을 바꿔준다.
마지막 데이터 핸들링으로서, 초기에 설정했던 kind 변수 즉, 분석을 원하는 장비 지정값이 따로 있는 경우, 이를 기준으로 필터링할 수 있는 조건문을 아래처럼 추가한다.
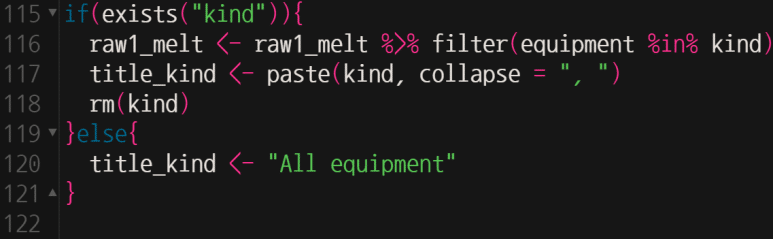
즉, kind 변수가 존재할 경우(앞에 # 표시를 제거한 경우), 무기가 kind에 지정된 값만 필터링한다는 의미고, kind 변수가 존재하지 않으면, 따로 필터링하지 않고 전 무기를 분석하겠다는 의미이다.
위 title_kind는 그래프 제목에 표시할 변수를 미리 생성한 것으로, 이를 통해 조건(kind 변수 통한 무기 선택) 지정 여부를 그래프에서 쉽게 파악하기 위해 해 놓은 장치이다.
시각화(Visualization)
이제 그래프로 그려보자.
(kind를 지정하지 않고, 주석(#) 처리한 경우)
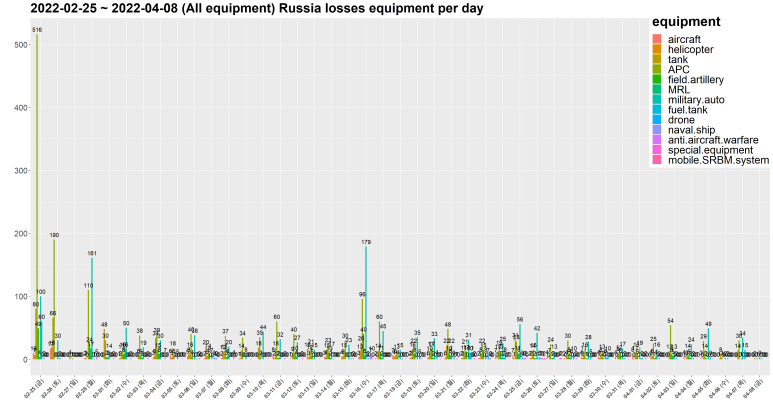
무기 종류가 많아 파악이 어렵다.
따라서 kind 값을 따로 지정해 특정 무기들만 표시해보자.
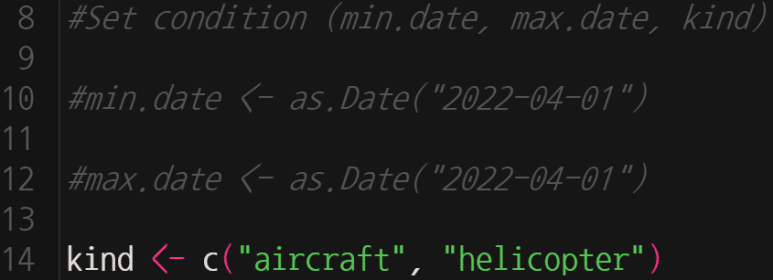
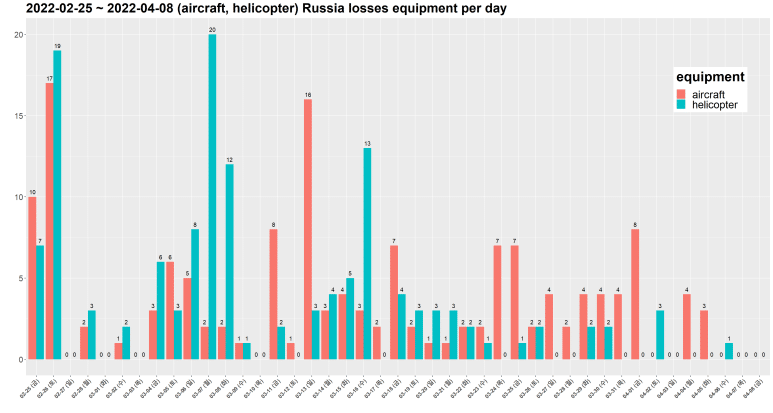
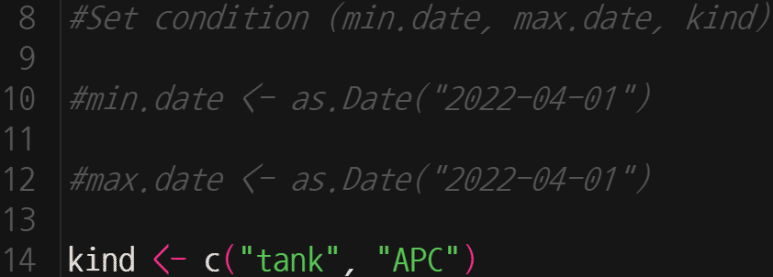
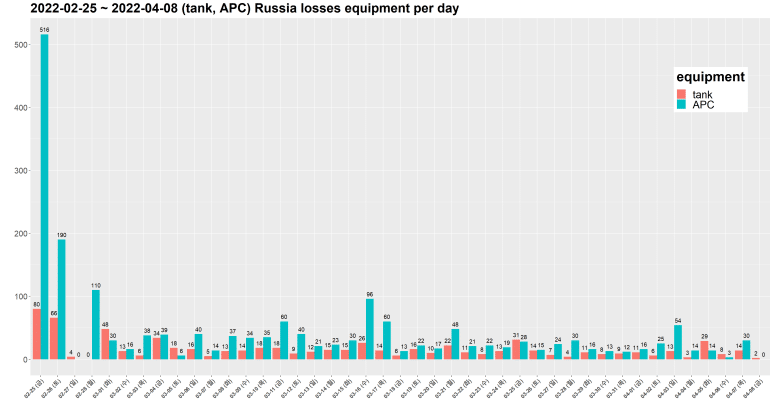
이번엔 tank, APC를 분석해보자.
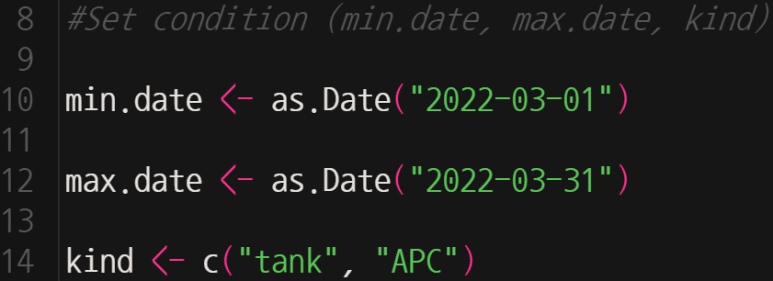
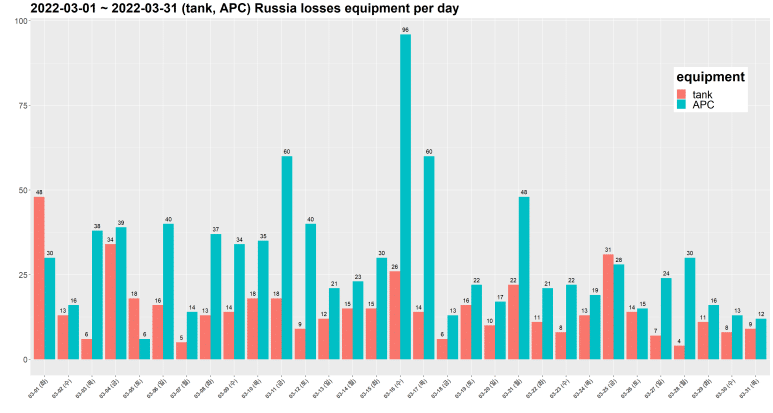
이번엔 날짜도 동시 지정해보자. 3월 한 달간의 tank, APC 분석
상기 자료는 캐글에 등록 완료하였다.